
When you chat with an AI like ChatGPT, have you ever wondered:
" How does it know what I’m talking about? "
The answer lies in context embeddings, which are the mathematical heartbeat of every Large Language Model (LLM).
Embeddings turn your words, sentences, and even emotions into vectors, multidimensional representations of meaning. These vectors help the model understand relationships, intent, and context, enabling it to respond intelligently instead of randomly.
Language as Geometry
Large Language Models (LLMs) like GPT, Claude, and Gemini don’t understand words; they understand relationships between them.
Using embeddings, every token (a small chunk of text) is transformed into a vector, a mathematical point in a high-dimensional space.
Two words with similar meanings (like king and queen) end up close together in that space, while unrelated words (like banana and philosophy) are far apart.
This is how the model learns that:
Language becomes math.
Meaning becomes geometry.
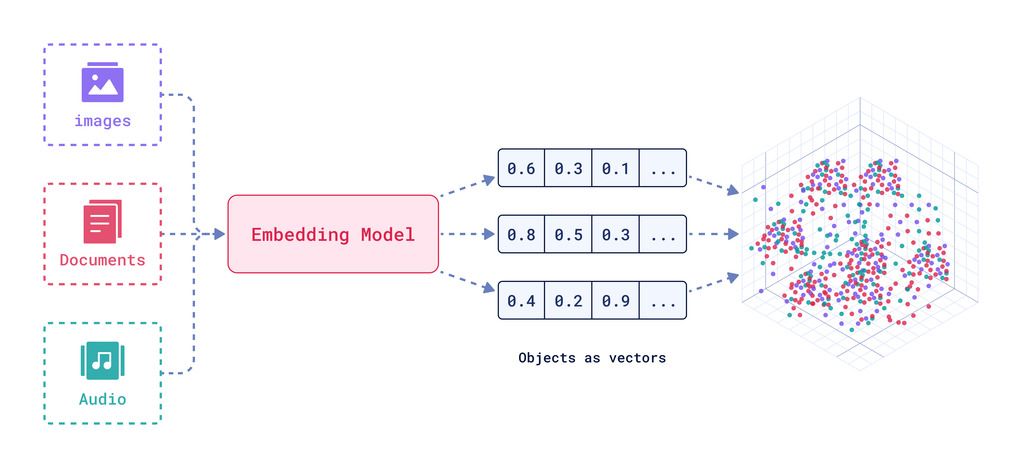
Explanation: This diagram demonstrates how any kind of media (text, audio, video, image) can be converted to simply a set of real numbers, which we call a high-dimensional vector.
The Model Doesn't "Know" - It "Infers" from Context
Imagine asking ChatGPT:
Who is the President?
If this question stands alone, the model has to rely on its pre-trained knowledge and patterns it learned during training to infer an answer.
But if you say:
We were talking about France. Who is the President?
Now, the context changes the entire meaning of your question.
The model embeds both sentences, finds relational meaning, and realises that you mean the President of France.
Context Defines Relevance and Focus
In a human conversation, you automatically know what the topic is because of shared context.
LLMs mimic this by using attention mechanisms, which are mathematical functions that decide which parts of the context to “focus” on more strongly.
For example, if the model is answering:
What color was the car that Joe drove to the conference?
It doesn’t scan every token equally. It pays more attention to tokens like “Joe,” “car,” and “conference.”
The embedding of the entire passage helps it weigh these words properly to generate an accurate answer.
That’s what makes the model’s response coherent: attention powered by contextual embeddings.
Let's consider the sentence "Multiple river banks in nature" and look at the diagram of the embedding of the word bank with respective to other words/tokens:
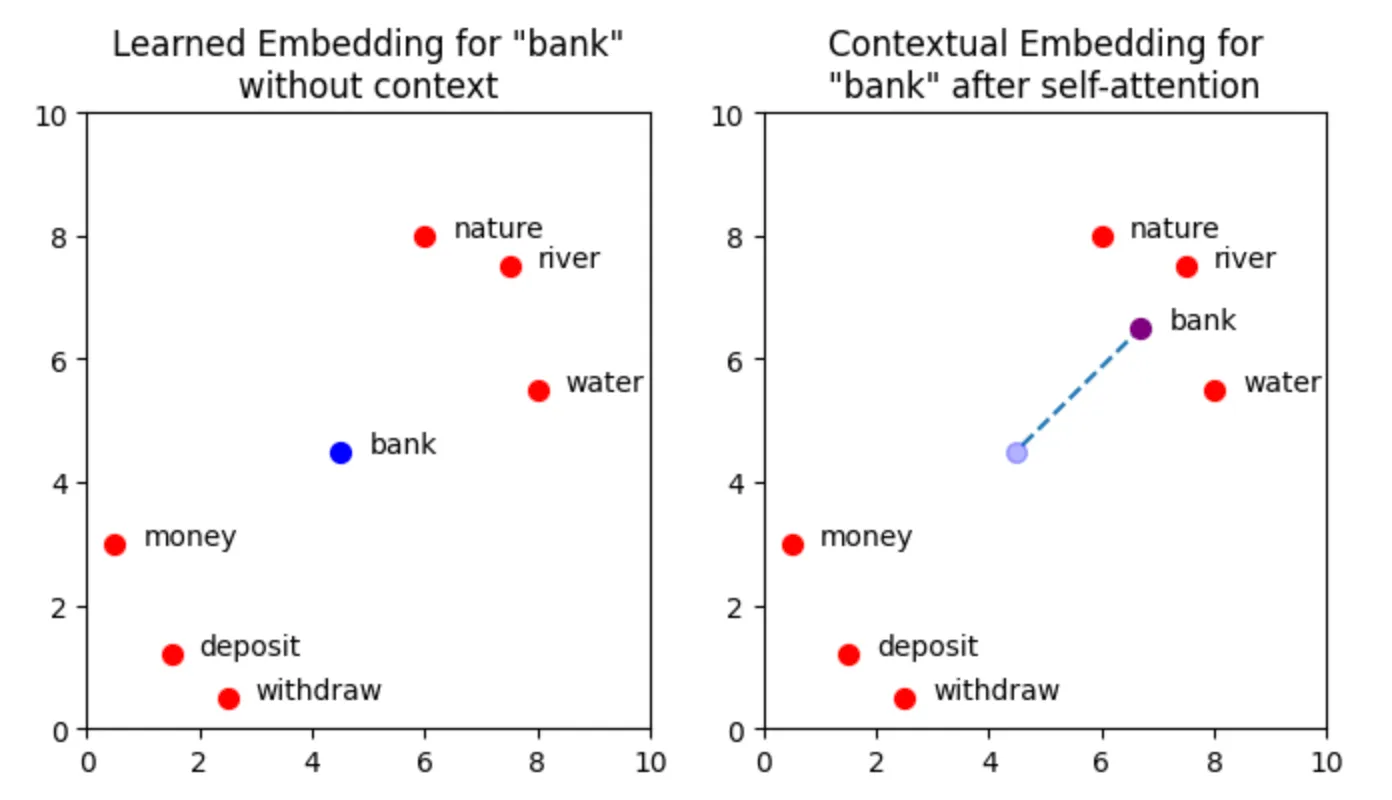
Explanation: This diagram depicts how the word "bank" in the sentence depends and changes its context based on the other words present.
Conclusion
Embeddings are the invisible bridge between language and logic. They allow machines to translate the fluidity of human expression into mathematical understanding. But what truly makes an LLM intelligent isn’t just its ability to store information, but it’s its ability to contextualise it.
This is what we are solving for at Alchemyst AI. If you need context connected across data sources for your AI agents to be truly versatile, we've got you covered! We mimic the neural cortex of the brain that is responsible for understanding the world in humans - but grounded deterministically so that you don't miss a beat if (or when) your agent falters.
If you're an enterprise and are curious about how we can help, feel free to book a demo!




