AI Agents talk.
Alchemyst helps them listen
A scalable memory-first system that dynamically extracts and retrieves key conversational facts - delivering 20% higher accuracy over SOTA on the PopQA benchmark with 95% reduction in development time.
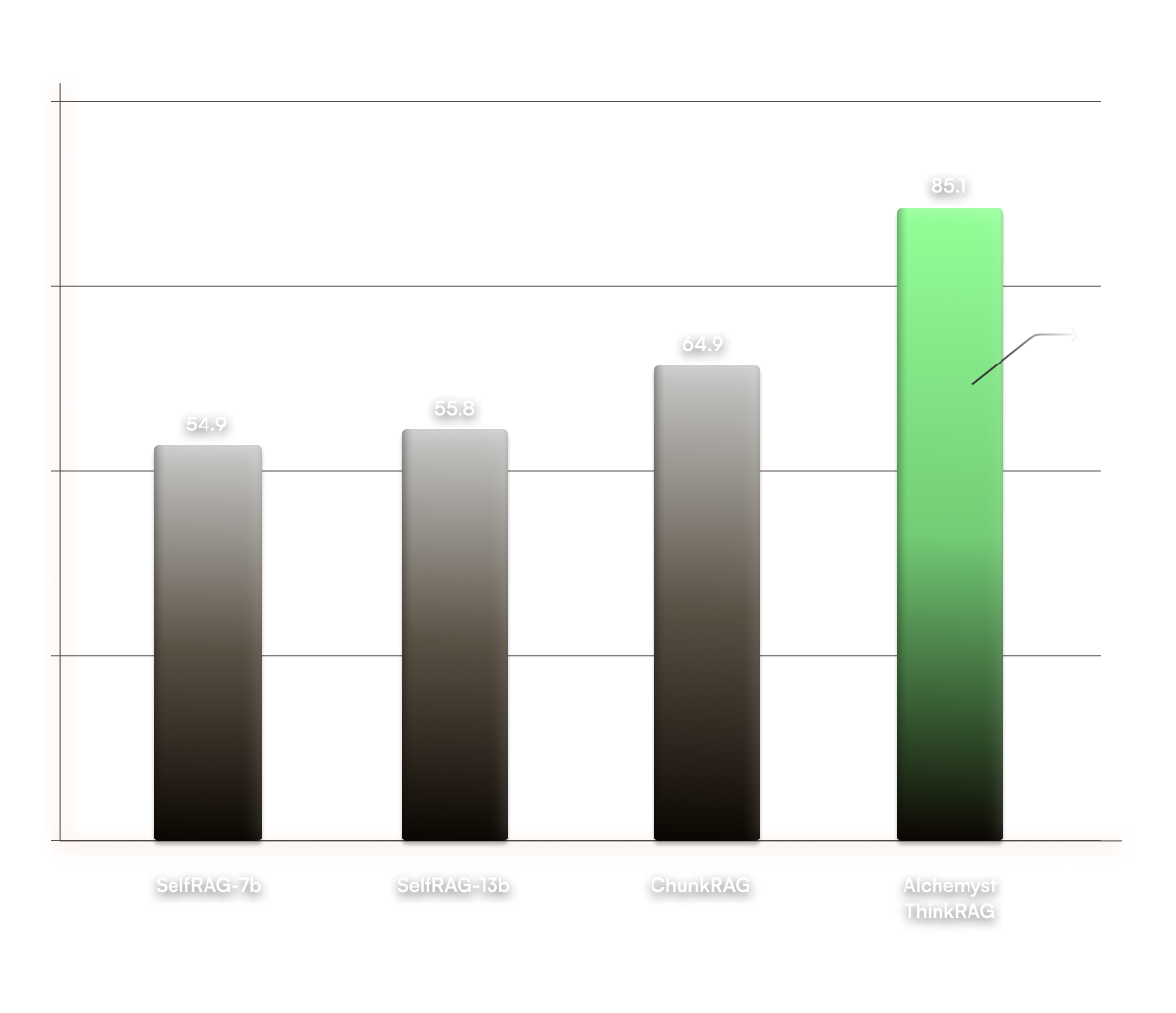
Benchmarking Alchemyst
Modern AI agents often suffer from high operational costs, limited task completion, and long development cycles - making it difficult to scale AI systems efficiently. Simply fine-tuning LLMs or increasing infrastructure fails to address these bottlenecks at the root.
Alchemyst tackles these challenges head-on with a context-first memory layer and optimized AI infrastructure that drastically reduces cost, boosts performance, and shortens time-to-launch.
Across real-world deployments, Alchemyst has demonstrated:
- ~40% lower interaction cost by sending only relevant context to the LLM
- ~40% reduction in token usage, making AI more affordable to operate
- 95% decrease in dev time - from 6 months to under 2 weeks
- 2.2× revenue increase from agents built on the platform
- 33.7% improvement in task completion, achieving 99.7% success rate
By turning short-term agents into persistent, context-aware systems, Alchemyst empowers teams to go from idea to production-ready AI in days - not months.
Under The Hood
A two-phase memory pipeline that extracts, consolidates, and retrieves only the most salient conversational facts - enabling scalable, long-term reasoning.

Alchemyst delivers a four-stage processing pipeline - Asym0, OKG Orchestration, ThinkRAG, and Context Marketing - connecting Data Sources to Agents/MCPs with comprehensive observability across all stages.

The architecture supports two deployment options: Managed Services leveraging MongoDB and QDrant for rapid deployment by development teams and small companies, and On-Premises Enterprise solutions with multi-source integration for organizations requiring data sovereignty and enhanced security.
This design enables scalable data orchestration while providing deployment flexibility to meet diverse organizational requirements and compliance needs.