
Introduction
“AI”, “AI”, “AI” - every CXO is busy selling the dream of the inflection point of this magical piece of technology that “might be even more fundamental than electricity”. At the root of it lies the vaunted prize of AGI - Artificial General Intelligence.
"AI is the most powerful technology humanity has ever created" ~ Sam Altman
“AI is the defining technology of our generation.” ~ Satya Nadella
“Artificial intelligence is the new electricity.” ~ Andrew Ng
“AI is one of the most profound things we’re working on as humanity … more profound than fire or electricity.” ~ Sundar Pichai
“AI will not destroy jobs - it will destroy tasks.” ~ Marc Andreessen
And the investments - both tangible and intangible, show for it. Trillions in investments, one new research paper every few minutes, one breakthrough almost every other week - AI has truly become mainstream.
The Reality Check: Compute isn’t everything
For the last few years, the entire AI industry has been obsessed with a single metric: Scale. We built larger data centers, trained on trillions of tokens, and celebrated every time a model’s parameter count jumped from 70 billion to 400 billion. The prevailing logic was simple: bigger compute equals better intelligence.
However, in late 2025, as we stretch the limits of LLMs, that reasoning is reaching a hard ceiling. The benefits of sheer processing power are waning, as we are discovering. Even if you increase the settings, the model will still be a clever but useful amnesiac if it is unable to remember a conversation's thread across several weeks or comprehend the subtleties of a particular company's past.
Context - the missing piece of AGI
The barrier for Artificial General Intelligence (AGI) is no longer the amount of knowledge a model possesses, but rather how well it applies that knowledge to the current situation. A model is a calculator, not an agent, if it can pass the bar exam but can't remember what you asked it ten minutes ago. It’s about understanding the problem it faces, sizing up the context of that problem, and then choosing the right approach. It must interpret the environment and make informed decisions rather than blindly applying a fixed method.There isn't a scale missing. It's context.
First, we got introduced to RAG with semantic search in 2021, by researchers at Meta’s FAIR - it showed how LLMs tend to use context supplied within the prompt itself to generate answers. But then, how do you find data that goes beyond traditional keyword-based search? Enter Vector Search, which had its boom from mid-2023 to late 2024.
But then, how do you store something like “after this”? Since the vectors can’t hold “state” or “sequence”, you cannot use simple RAG for this. Consider the example of the following conversation:
User: Hey, I would like to buy milk chocolate. [Stored in vector store]
AI Assistant: Sure, let me look up [Stores “user likes milk chocolate”]
User: No, let it be, I would like to buy Dark Chocolate before that [Need to update, but how?]
This is where Vector Search hits a wall. If you query the vector database now, it sees two mathematically similar facts: "User wants milk chocolate" and "User wants dark chocolate." It has no concept of time, correction, or priority. It just sees two conflicting desires floating in space.
To solve "before that" or "instead of this," we must evolve beyond simple similarity. We need structure.

But, we aren’t solving for context right. Yet.
[The industry is fragmented - memory and search are treated differently]
Currently, we treat "Memory" and "Knowledge" as two distinct, non-overlapping disciplines:
- Memory is treated as a fading log of user interactions ("Chat History").
- RAG (Retrieval-Augmented Generation) is treated as a hard database query for static business documents.
However, real Context is multidimensional. The all-encompassing element - it is neither solely memory nor exclusively RAG. It is the liquid condition where both merge. Considering them as isolated entities, we are overlooking the broader perspective. True AGI will be achieved when we cease creating distinct systems for "previous conversations" and "static documents," and instead develop a cohesive Context Layer that comprehends their interconnections. This context layer will act as the fabric which will make information useful, not just available.
And the state shows for it.

The research community, just like the tooling ecosystem, still draws a bold line between “knowledge retrieval” and “memory.” On one side sit the RAG benchmarks - PopQA being the most popular of them. PopQA gives a model a clean, single-sentence question (“What’s the capital of Louisiana?”) and scores whether the answer string is correct. It is brilliant at measuring long-tail factual recall, but everything about the test assumes knowledge is static and context-free - no speaker, no timestamp, no conversational thread, just a fact plucked from Wikidata.
On the other side sit the memory benchmarks - LongMemEval is the flagship. Here, the model swims through hundreds of thousands of tokens of prior dialogue and is quizzed on what the user said three weeks (and fifty sessions) ago. The benchmark punishes a system that forgets, misdates, or hallucinates an update; it rewards one that can say “I don’t know” when the chat never contained the answer. Yet every question is deliberately answerable inside the chat log. The benchmark never asks the model to leave that log and consult a spec sheet, an error log, or yesterday’s sales spreadsheet.
The result is a pair of orthogonal leaderboards that feel impressive - until you try to build a real workplace assistant. Picture Monday morning:
Yesterday in Slack
“Migration script blew up on column `user_id` - blocking deploy.”
The run-book (internal Confluence page)
“If `user_id` overflow occurs, switch to BIGINT and backfill with script B.”
At 9am, your teammate asks, “Did we patch the script, and what’s the error rate now?”
A PopQA-optimised bot will happily spit out a definition of BIGINT from your business data; A LongMemEval-optimised bot will recall the panic message from Slack but have no clue where the run-book lives.
Neither benchmark forces the model to “braid” those two strands - yesterday’s conversation and the evergreen documentation - into one fluent answer. The gulf between them is precisely where context falls apart.
Until we evaluate systems on tasks that weave memory and retrieval together - “Remind me what blocker we closed yesterday and attach the Jira diff” - we will keep shipping assistants that either have the memory of a goldfish or the social awareness of a search box. A true Context Layer must treat chat logs and external knowledge as different views of the same graph, not rival data silos. The benchmarks - and the products they inspire - need to evolve accordingly.
Reimagining context with Alchemyst
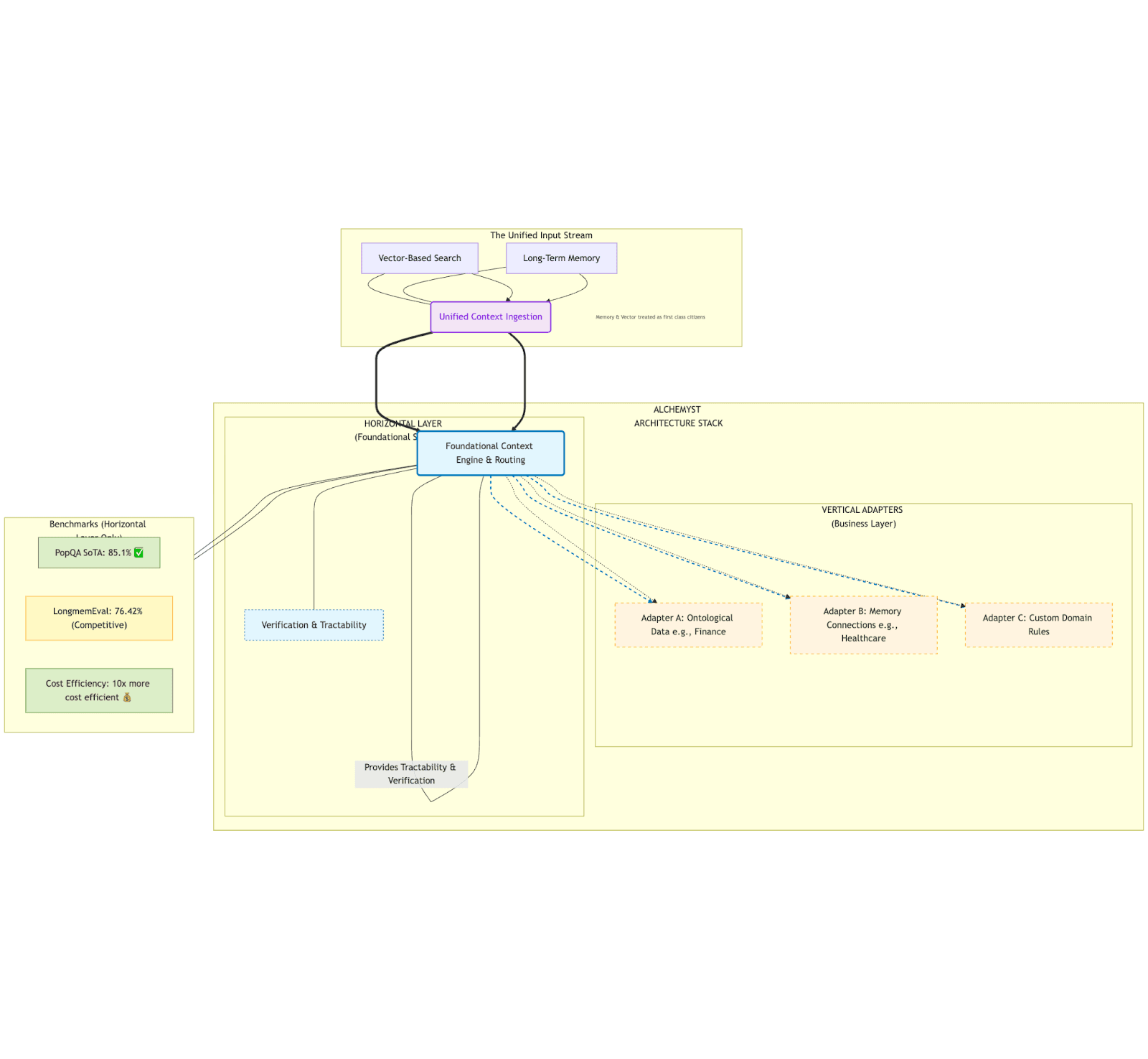
Alchemyst achieves state-of-the-art (SoTA) performance @ 85.1% on PopQA, while achieving the previous State-of-the-art (SoTA) on LongmemEval @ 76.42%, very recently surpassed by SuperMemory, whilst remaining 10x more cost efficient than similar products - whilst also providing tractability and verification from the ground up.
This is achieved by changing the fundamental design of context engineering - by separating context engineering into two segments:
A horizontal layer - a base substrate for context engineering to take place
A business specific, “vertical” adapters - for different types of business specific ontological data, memory-based connections, etc
Notice that memory and vector-based search aren’t divided here - it’s what the agent can decide on its own. Memory and vector-based search are both treated as first class citizens of the overall context layer.
The reported benchmarks are simply on the horizontal layer, leaving further room for businesses to adapt this context to their domain-specific use-cases.
The Biological Analogue: How context is shaped up in the human brain
Context isn’t a “memory only” problem - it’s a structural plasticity problem. The brain doesn’t just retrieve memories; it grows circuits around the problems it solves repeatedly.
The Horizontal Layer: The Stable Executive & Memory Substrate
Two structures form the brain’s context foundation: the prefrontal cortex (PFC) and the hippocampus. The PFC is the executive editor - it doesn’t store your childhood; it decides what matters right now. The hippocampus is the indexer - it tags, routes, and patterns incoming signals, but it doesn’t “store” memories either; it reconstructs them from cortical fragments on demand. Together, they create a lean, domain-agnostic substrate for real-time reasoning.
This is analogous to the horizontal layer in our stack, creating an equivalent of a “contextual operating system” with PFC-like efficiency and mimicking plasticity induced by hippocampal indexing. This eliminates the latency tax of chaining retrieval and generation.
The Horizontal Layer never changes between deployments. It is the stable substrate that stays constant whether you’re diagnosing a patient or detecting fraud.
The Vertical Adapters: Occupational Neuroplasticity
The famous London Taxi Driver study revealed a truth: the drivers’ posterior hippocampi reorganized their cortical connections, forming a specialized circuit linking spatial memory to the posterior parietal cortex. The plasticity wasn’t in the hippocampus alone; it was in the hippocampal-cortical circuit that the occupation demanded.
Vertical Adapters in the context layer are synthetic instantiations of this process. When you deploy a finance adapter, you’re inducing targeted neuroplasticity - the Horizontal Layer’s PFC begins routing finance queries through a new circuit that has grown domain-specific pattern recognizers for credit risk, ontological relationships for derivatives, and memory traces for regulatory logic.
This is why we call memory a “first-class citizen”: the adapter doesn’t retrieve documents; it reconstructs reasoning pathways the way a surgeon’s brain reconstructs the steps of a procedure. The adapter is not a database; it is a domain-specific hippocampal-cortical circuit that has been trained to grow into the architecture.
The brain’s power is the bidirectional loop: the PFC queries the hippocampal-cortical circuit, the circuit returns a compressed schema, and the PFC verifies its relevance against current goals. Alchemyst mirrors this: the Horizontal Layer decides when to invoke an adapter, the adapter returns a domain-shaped context manifold, and the Horizontal Layer’s tractability engine verifies every step back to source.
This is why our 85.1% baseline is just that - a baseline. When a bank plugs in its fraud adapter, the system doesn’t get “smarter” in the generic sense. It structurally shifts, becoming as specialized as a taxi driver navigating London, yet as efficient as a grandmaster at a chessboard. The accuracy gains aren’t from more data, but rather from architectural reorganization.
The reported benchmarks are what the Horizontal Layer achieves with general knowledge. The vertical adapters are what happen when your AI starts doing the job.
Conclusion
Context is a homogeneous superposition of memory and recall-based search, and that’s a fact supported by biology. This is what we’re building at Alchemyst - a context layer that can plugin with LLMs and AI agents to actually mimic and form an artificial “second brain”.
Ready to upgrade your agent’s context layer? Don't settle for static data retrieval. Give your AI the specialized "Hippocampus" it needs to master your industry. Sign up on the Alchemyst Platform now!
In our next article, we will be showing how to tractably do so, mimicking the human brain.