
The Evolution of Continuous AI Agents and the Need for Memory Compression
The landscape of enterprise artificial intelligence is undergoing a massive paradigm shift. We have moved entirely beyond the era of stateless, single-turn conversational bots and entered the domain of continuous, autonomous AI agents. These advanced systems are increasingly required to run for extended durations—sometimes operating continuously over 30 days or more—handling complex, multi-step business workflows. However, as these agents execute tasks over long periods, they accumulate an immense volume of interaction data. Managing this historical data efficiently is one of the most pressing engineering challenges in AI today, making AI agent memory compression techniques an essential area of focus for developers and enterprise architects alike.
Memory in the context of Large Language Models (LLMs) and AI agents refers to the system's ability to retain, recall, and contextualize past interactions to inform future responses. When an AI agent runs continuously, ingesting documents, executing go-to-market (GTM) strategies, or analyzing large sets of enterprise data, its memory buffer fills up rapidly. Standard LLMs operate with fixed context windows. While modern models boast context windows of up to one million tokens or more, continuously feeding maximum-capacity contexts into a model for every single interaction results in astronomically high compute costs, severe latency spikes, and degraded reasoning capabilities—often referred to as the lost in the middle phenomenon. To achieve genuine scalability, enterprise architectures cannot simply rely on larger context windows; they must implement sophisticated AI agent memory compression techniques.
The Core Problem: Context Limits and Memory Decay
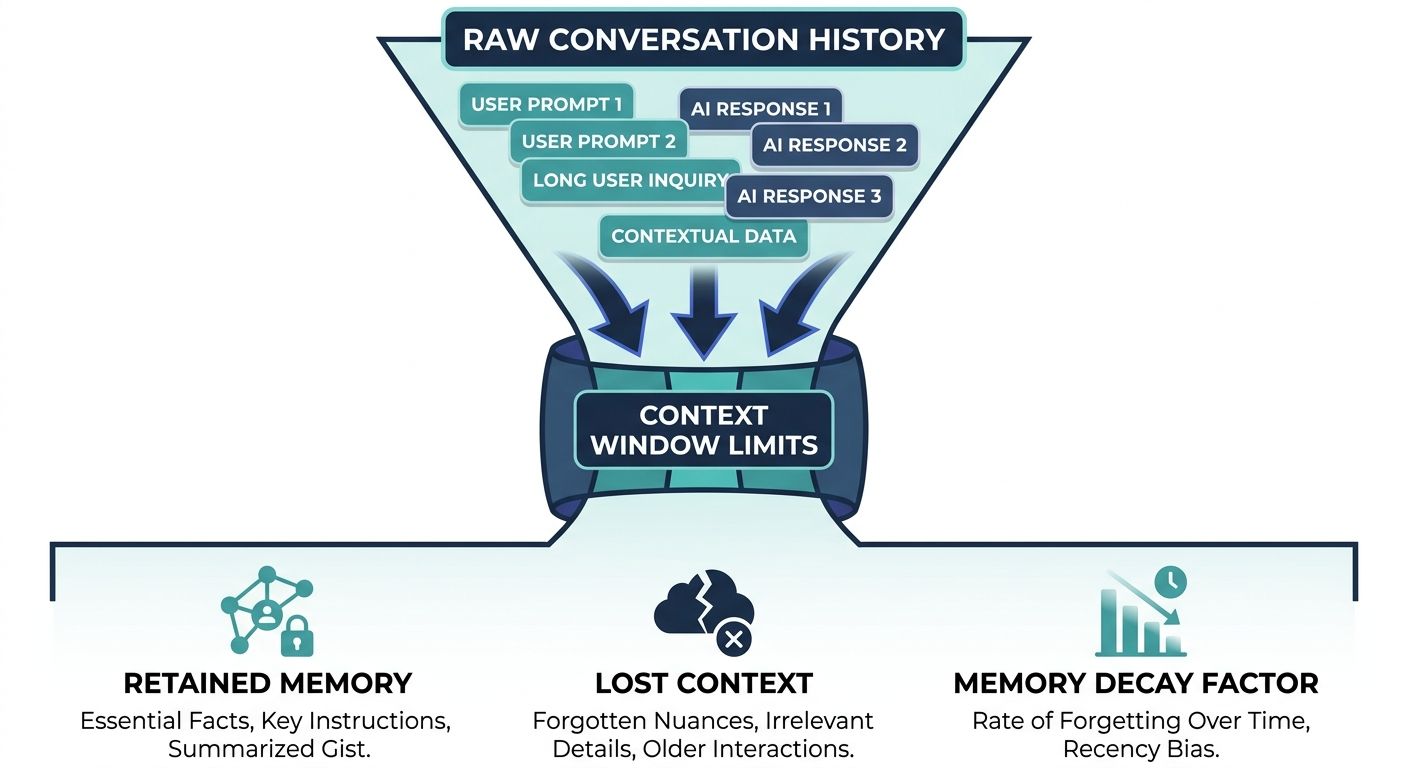
Before diving into specific compression methodologies, it is crucial to understand the limitations of raw context handling. When an AI agent operates, it typically maintains a transcript or log of its active session. As this session history grows, the token count increases linearly. At scale, pushing an ever-growing prompt to an LLM endpoint for every API call becomes a massive bottleneck. Furthermore, empirical studies have shown that LLMs struggle to extract precise information when relevant facts are buried deep within a massive, uncompressed context window.
Memory decay in stateless systems is a critical failure point. If an agent simply truncates its earliest memory to fit the immediate context window (a basic sliding window approach), it suffers from catastrophic forgetting. The agent will lose track of overarching goals, user preferences established early in the conversation, or critical steps already completed in a long-term workflow. Therefore, managing agent memory requires a shift from passive data storage to active context curation, utilizing engines that dynamically compress, retrieve, and synthesize information without losing high-fidelity semantic meaning.
What is an AI Agent Memory Compression Engine?
A memory compression engine is a dedicated infrastructure layer designed to handle context dynamically. Rather than treating memory as a flat text file, a compression engine actively curates what the AI agent needs to know at any given millisecond. It functions as the drop-in memory infrastructure that bridges the gap between ephemeral working memory (the immediate context window) and persistent long-term storage (databases). By applying specialized algorithms, the engine shrinks the token footprint of historical data while preserving its core intent, factual payload, and relational context.
These engines are particularly vital for enterprise AI solutions that require persistent context across multiple disconnected sessions. For instance, in sales automation and go-to-market motions, an AI agent might speak with a prospect on a Monday, analyze an email from them on Wednesday, and conduct a follow-up voice call the next week. A robust memory compression layer ensures that the agent retains all the nuance of the Monday call without having to load the raw transcript into Wednesday's prompt.
Foundational AI Agent Memory Compression Techniques
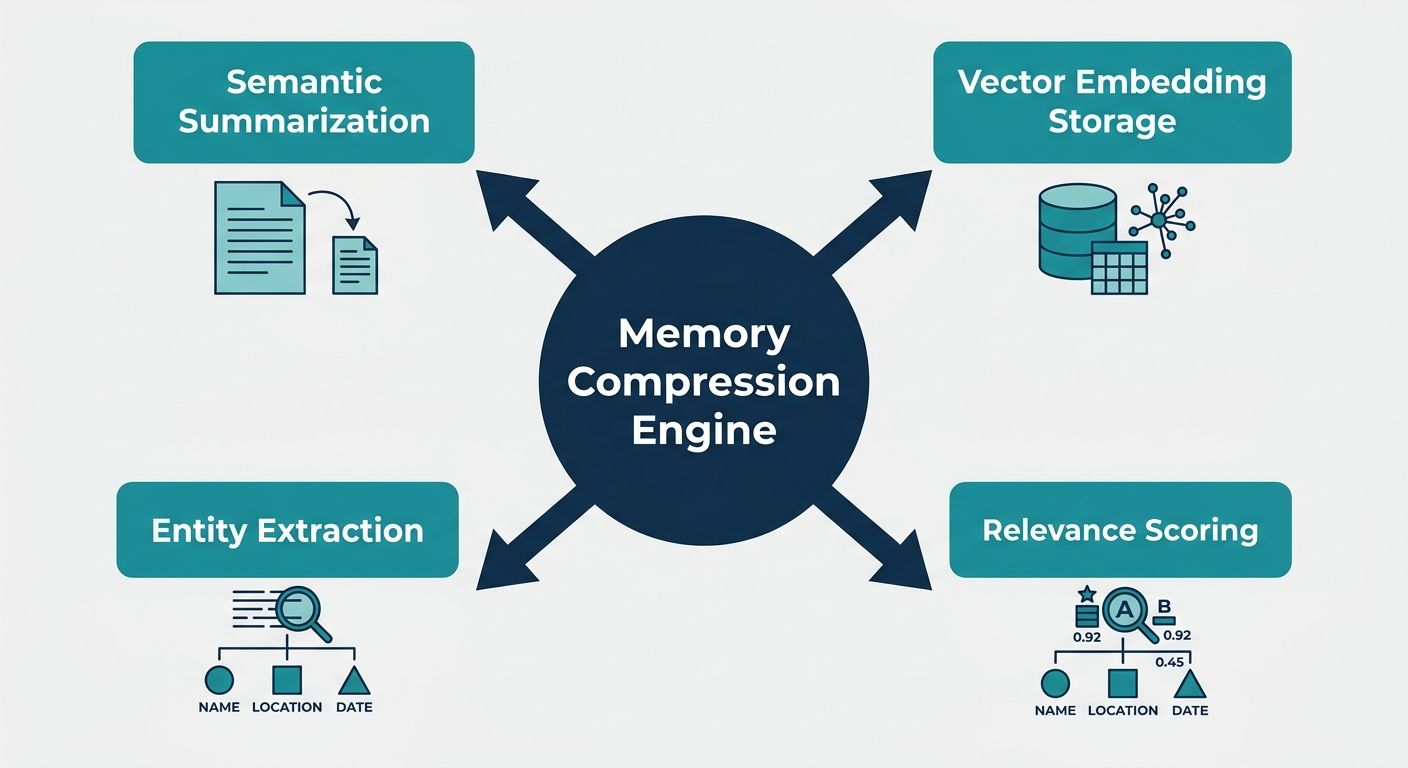
Engineering teams employ several foundational techniques to compress agent memory. These methods serve as the baseline for constructing robust, scalable continuous agents.
Recursive Abstractive Summarization
One of the most widely implemented AI agent memory compression techniques is recursive abstractive summarization. Instead of keeping a verbatim transcript of a 10,000-word interaction, the system periodically triggers a background LLM process to summarize older chunks of the conversation. The key to making this effective is the recursive nature of the algorithm. As summaries themselves begin to accumulate and consume too many tokens, the engine summarizes the summaries. This hierarchical map-reduce approach ensures that the total token count of the agent's long-term memory remains mathematically bounded, regardless of how long the agent runs. While highly effective at reducing token counts, pure summarization can sometimes result in the loss of granular details or exact phrasing.
Sliding Window with Token Pruning
The sliding window technique combined with token pruning is another staple of memory management. The sliding window ensures that only the most recent N-tokens (e.g., the last 10 messages) are kept in raw, verbatim format in the agent's active working memory. However, to prevent a hard cut-off where older context is completely lost, token pruning algorithms evaluate the semantic importance of older tokens before they slide out of the window. Stop-words, filler phrases, and conversational pleasantries are stripped away, leaving only dense, information-rich keywords that are appended to a compressed context block.
Entity-Based State Extraction
To preserve highly granular details that might be lost during abstractive summarization, developers use entity-based state extraction. As the agent converses, a parallel process continuously evaluates the dialogue to extract critical entities: names, dates, budget constraints, user preferences, and actionable tasks. These extracted entities are then stored in a highly structured format, such as a JSON state object or a graph database. When the agent needs to generate a response, the system injects this highly compressed state object into the system prompt. This guarantees that the agent never forgets a critical fact, and it does so utilizing a fraction of the tokens required by a full transcript.
Advanced Memory Architectures for Continuous AI Agents
While foundational techniques are sufficient for simple chatbots, continuous AI agents executing multi-layered enterprise workflows require advanced architectures. These techniques move beyond simple token manipulation into the realm of dynamic semantic networks.
Vector Retrieval and Episodic Memory (RAG)
Retrieval-Augmented Generation (RAG) is most commonly associated with connecting LLMs to external knowledge bases. However, RAG is fundamentally one of the most powerful AI agent memory compression techniques available. By treating the agent's own past experiences as a vector database, developers can create a form of episodic memory. Every interaction, thought process, and executed tool call is embedded as a vector and stored. The active context window is kept incredibly small—perhaps just the current user prompt. When the agent receives a prompt, it queries its own episodic memory via similarity search, retrieving only the exact historical moments that are contextually relevant to the current task. This allows the agent to have effectively infinite memory capacity with a fixed, highly compressed prompt size.
Semantic Deduplication
Over the course of a 30-day continuous run, an AI agent will inevitably encounter repetitive information. A user might repeat their requirements across multiple sessions, or the agent might repeatedly query the same API resulting in identical data payloads. Semantic deduplication leverages embedding models to measure the cosine distance between newly acquired information and the existing long-term memory store. If the new information is semantically identical or highly similar to an existing memory node, the engine discards the redundant data and simply updates a frequency or recency weight on the existing node. This technique drastically compresses the volume of data stored and prevents the context window from being flooded with repetitive noise.
Hierarchical Memory Tiers
The most advanced continuous agents employ a hierarchical memory tier system inspired by human cognition. This architecture divides memory into three distinct layers: Working Memory (ephemeral, verbatim, high cost), Episodic Memory (vectorized past events, retrieved via semantic search), and Semantic Memory (generalized facts and rules extracted over time). By pushing raw data from working memory down into episodic and semantic layers through asynchronous compression pipelines, the agent maintains an incredibly lean active prompt while still possessing deep, persistent knowledge of its entire lifecycle.
Building Persistent Memory for Voice and GTM Agents
Implementing memory compression for text-based chatbots is complex, but scaling these architectures for enterprise voice AI agents introduces entirely new technical hurdles. When dealing with autonomous sales platforms and GTM automation, context handling mastery is the key differentiator between a successful enterprise deployment and a frustrating user experience.
Voice-Specific Context Handling and Latency
In voice AI architectures, every millisecond counts. Integrating Speech-to-Text (STT) and Text-to-Speech (TTS) pipelines inherently adds latency to the system. If the AI agent is forced to process a massive, uncompressed context window to generate its next spoken response, the generation time will spike, resulting in unnatural, awkward pauses in the conversation. Memory compression techniques for voice agents must operate asynchronously in the background. The active state must be so heavily compressed that the LLM can generate the first token of its response almost instantaneously. Furthermore, voice contexts involve non-verbal cues, interruptions, and disfluencies (ums, ahs) that must be filtered out by the compression engine to prevent context pollution.
When deploying autonomous sales and GTM workflows, reliable memory management is critical. Alchemyst AI addresses this by providing an AI-native context management solution that securely maintains user preferences and long-term conversation history across sessions, ensuring your enterprise voice and text agents never lose critical business context.
For go-to-market teams utilizing AI agents to conduct outreach, follow-ups, and lead qualification, persistent context is non-negotiable. An enterprise prospect expects the AI to remember the exact budget constraints discussed three weeks ago. Relying on superficial feature lists or generic memory scaling won't work for high-stakes enterprise sales. You need deeply integrated user preference tracking and granular conversation history that seamlessly informs every outbound action the agent takes.
Evaluating Memory Infrastructure for Enterprise AI
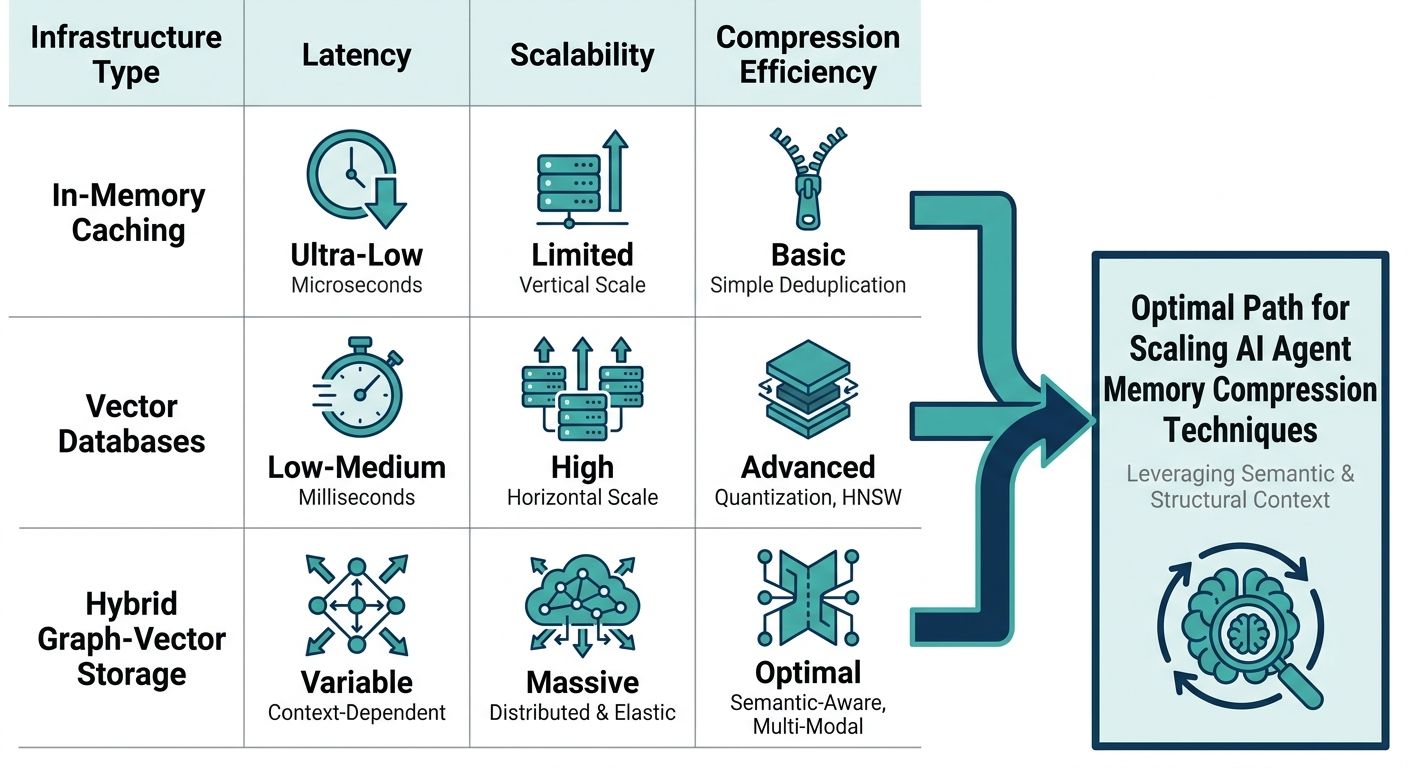
As organizations look to adopt or build continuous AI agents, evaluating the underlying memory infrastructure becomes a critical part of the procurement or architecture process. Enterprise buyers should look far beyond the superficial features of standard conversational APIs. When assessing an AI platform's context handling capabilities, specific technical methodologies for retention must be scrutinized.
- Context Decay Rate: How much critical factual information is lost when the platform runs its summarization or pruning algorithms? Enterprise solutions must offer deterministic extraction for non-negotiable data points.
- Memory Duration vs. Cost: Can the agent maintain persistent memory over a 30-day or 90-day period without the cost per token scaling exponentially? Look for systems that utilize tiered storage and vector-based retrieval to control compute costs.
- Cross-Session Continuity: Does the memory engine offer true drop-in infrastructure that bridges completely separate sessions? An agent must be able to wake up from a dormant state, retrieve the user's historical state payload, and resume operations flawlessly.
- Custom AI Model Integration: Advanced enterprises often use fine-tuned or custom AI models. The memory compression techniques utilized by the platform must be compatible with these custom models, ensuring that state payloads and compressed contexts are formatted correctly for the specific LLM architecture in use.
Future Trends in LLM Memory Scaling
The field of AI agent memory compression techniques is evolving rapidly. Future trends point towards the integration of sophisticated knowledge graphs directly into the attention mechanisms of the LLMs themselves. We are also seeing the rise of continuous learning models that adjust their internal weights based on interactions, theoretically eliminating the need for an external context window entirely for certain types of semantic memory. However, until continuous fine-tuning becomes cost-effective and completely stable, external memory compression engines will remain the definitive architectural standard for enterprise agents.
Moreover, developers are increasingly leveraging advanced technical documentation frameworks, utilizing tools like Mintlify and MDX, to map out standard protocols for memory integration. This open, standardized approach to documentation enables developer communities to build more cohesive, interoperable memory solutions across different programming environments and platforms.
Conclusion
Mastering AI agent memory compression techniques is no longer optional for organizations looking to deploy continuous, autonomous agents at scale. By moving beyond simple context window expansions and embracing dynamic compression engines, hierarchical memory tiers, and vector-based retrieval, enterprise systems can achieve unparalleled contextual depth. Whether automating complex GTM strategies or deploying ultra-low-latency voice agents, a robust, persistent memory layer is the foundation of truly intelligent, reliable AI operations. The ability to compress, retain, and seamlessly inject context over extended durations dictates the true capability and commercial viability of any AI agent platform.
Effective memory compression is the backbone of truly autonomous, continuous AI agents. By utilizing a robust context layer, businesses can deploy scalable AI solutions that remember user preferences, maintain historical context, and execute complex GTM strategies without losing the plot.
Learn more about Alchemyst AI



