
Introduction to Production-Ready AI Agent Infrastructure
The landscape of artificial intelligence is undergoing a massive shift, transitioning from passive generative tools to highly autonomous, task-oriented AI agents. While building a demonstration or a Proof of Concept (POC) for an AI agent has never been easier, deploying these systems into a reliable, enterprise-scale environment remains a profound challenge. Organizations frequently encounter a steep "demo-to-deployment" gap where local scripts fail to handle real-world latency, state management, and edge cases. To bridge this divide, engineering teams require a highly prescriptive, production-ready AI agent infrastructure reference architecture.
This comprehensive guide details the foundational pillars required to architect, deploy, and maintain resilient AI agents. Whether you are automating intricate customer service voice pipelines, designing intelligent task automation workflows, or building an AI-powered B2B content generation engine, the infrastructure underlying your agents must be scalable, secure, and observable. We will explore the critical layers of a robust reference architecture, delve into AI-native context management, address the unique complexities of voice AI infrastructure, and define the necessary MLOps tooling required for enterprise environments.
The POC to Production Chasm: Understanding the Deployment Gap
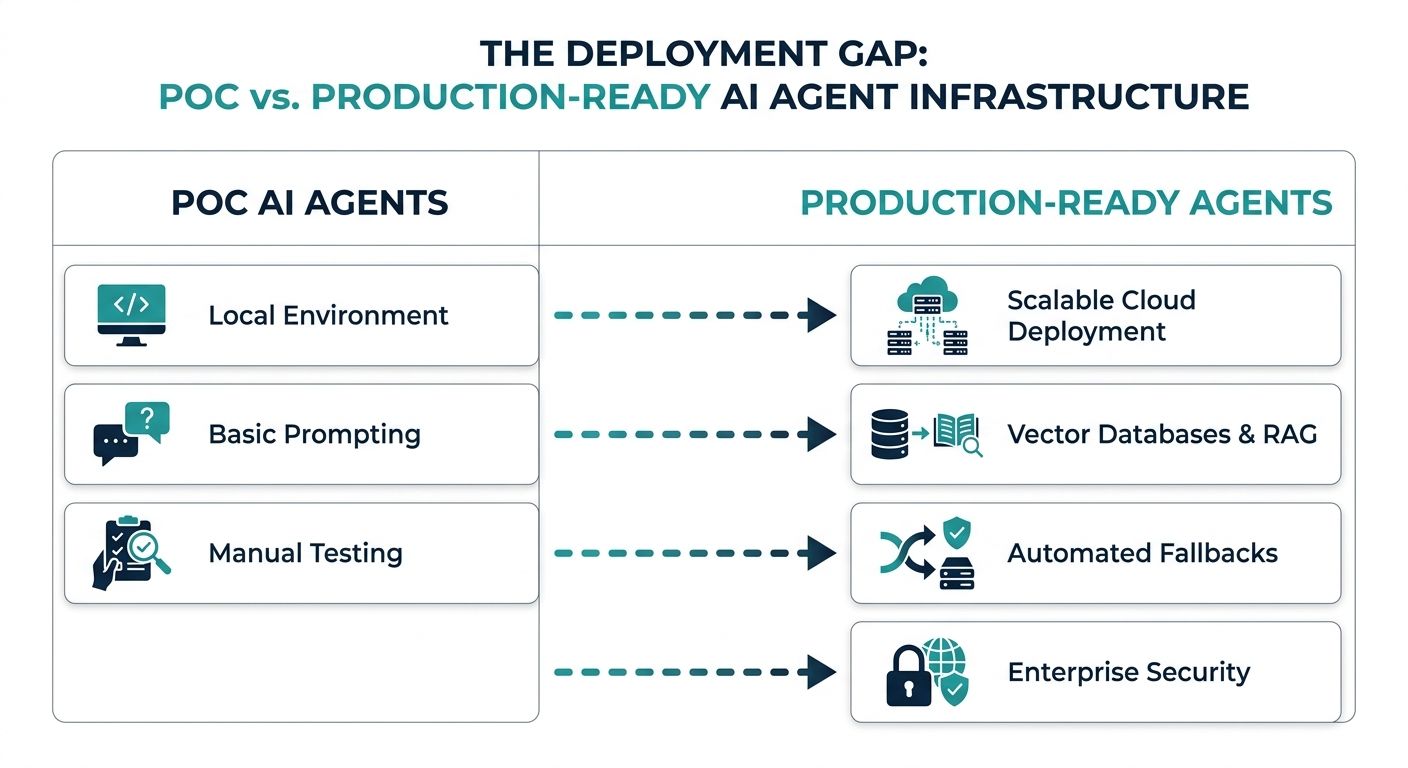
The journey from a Jupyter notebook or a local Python script to a globally distributed AI service is fraught with technical hurdles. Many competitors in the AI infrastructure space provide basic Application Programming Interfaces (APIs) or generic drop-in memory layers, but they often lack the prescriptive, end-to-end guidance necessary for true production readiness. When moving an AI agent to production, several critical failure points emerge.
First, state and context loss heavily degrades user experience. In a local environment, state is often maintained in simple arrays or ephemeral memory. In production, requests are stateless, routed through load balancers, and distributed across multiple worker nodes. Without a robust persistence layer, an agent will quickly "forget" the ongoing conversation or user preferences. Second, latency and throughput bottlenecks become highly apparent. Processing complex prompts, routing decisions, and invoking external tools take time. When scaled to thousands of concurrent users, unoptimized systems fail to meet acceptable latency budgets—especially in real-time voice applications. Finally, brittle integrations and tool executions can crash the system. Agents relying on external APIs must handle rate limits, timeouts, and unexpected payload structures securely.
Foundational Layers of the Reference Architecture
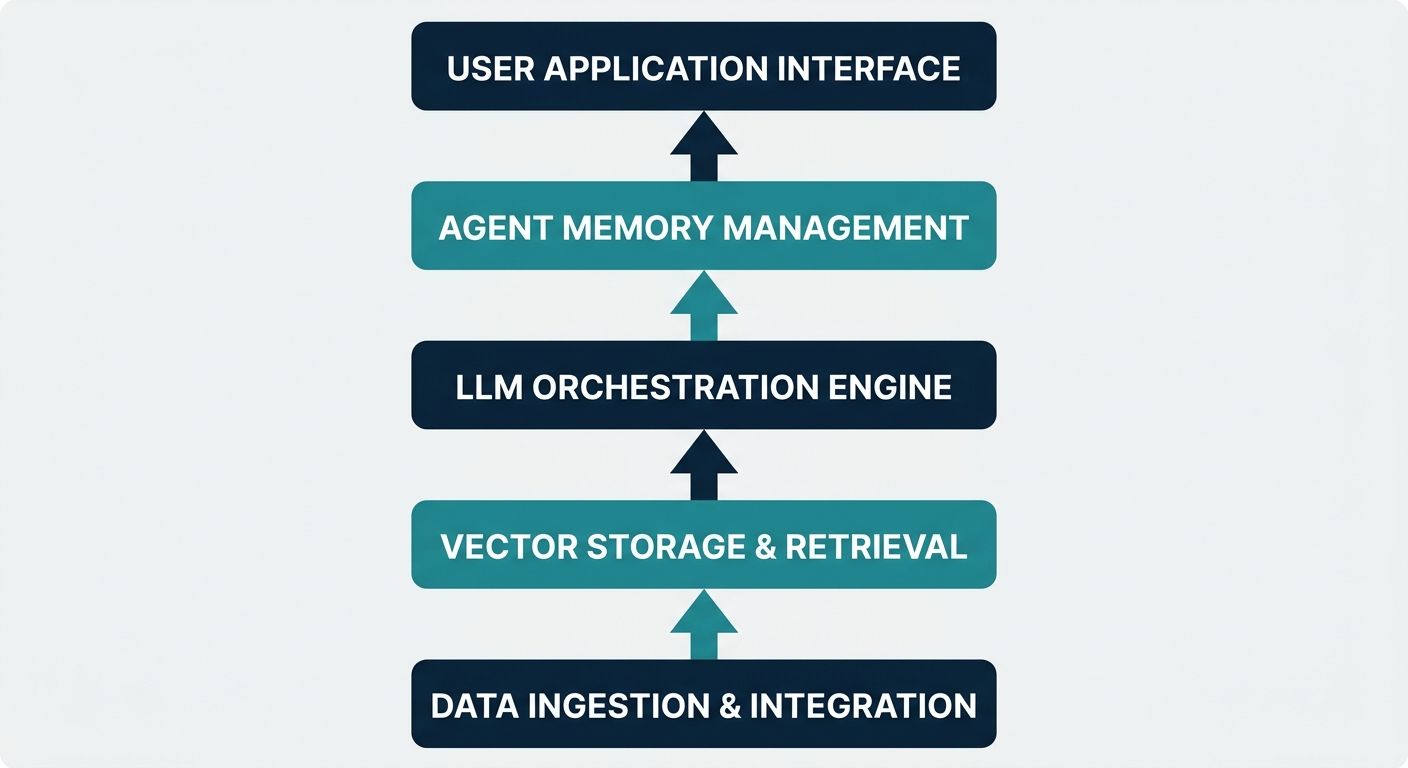
To overcome these challenges, a production-ready AI agent infrastructure reference architecture must be structured hierarchically. The architecture isolates specific concerns into dedicated services, ensuring that the orchestration, memory, tool execution, and deployment layers can scale independently.
1. The Routing and API Gateway Layer
At the edge of the infrastructure sits the API Gateway. This layer acts as the primary ingress point for all incoming traffic, whether it is text-based chat payloads or streaming audio over WebSockets. The gateway handles rate limiting, authentication (such as role-based access control), and request validation. For highly scaled enterprise deployments, this layer must dynamically route requests to the appropriate processing nodes based on the tenant, geographic region, and the specific AI model required. It essentially serves as the protective shield ensuring that only validated, authorized requests trigger compute-heavy AI operations.
2. The Orchestration and Reasoning Engine
The orchestration engine is the "brain" of the AI agent infrastructure. Unlike simple Large Language Model (LLM) wrappers that merely forward prompts and return responses, an orchestration engine manages the iterative loops of agentic behavior. It utilizes paradigms like ReAct (Reasoning and Acting) or Plan-and-Solve to break down complex user requests into smaller, actionable steps. Within a production architecture, this engine evaluates the user's intent, queries the context management system for historical data, selects the appropriate external tools to invoke, and synthesizes the final output. Crucially, the orchestrator must be designed asynchronously to prevent blocking threads while waiting for long-running LLM inferences or third-party API responses.
3. AI-Native Context Management
One of the most critical differentiators in a successful production deployment is how it handles memory and context. Generic memory drop-ins are insufficient for complex enterprise needs. A sophisticated AI-Native Context Management platform, like the core service provided by Alchemyst AI, operates beyond mere session persistence. It seamlessly bridges user preferences, historical conversation data, and dynamic enterprise knowledge bases into a unified, low-latency context window.
This layer typically involves a hybrid database approach: a highly available key-value store (like Redis) for immediate conversational turns and session state, coupled with a highly scalable Vector Database for long-term semantic retrieval. As the AI agent interacts, the context management system dynamically compresses, summarizes, and retrieves pertinent information, ensuring the LLM is neither starved of context nor overwhelmed by unnecessary tokens, which can drastically increase operational costs and latency.
4. Tool Registry and Secure Execution Environment
For an AI agent to perform meaningful actions—such as checking inventory in an e-commerce platform, updating patient records in healthcare, or fetching financial analytics—it requires access to custom connectors and tools. The Tool Registry acts as a centralized catalog defining the schemas, endpoints, and authentication methods for every available action. However, executing these tools in production introduces significant security risks. Therefore, the architecture must include a Secure Execution Environment. This is often implemented via sandboxed containers or serverless functions that isolate the tool execution from the core orchestration engine. If a tool fails, times out, or returns malicious data, the sandbox ensures the failure is contained, allowing the orchestrator to recover gracefully and inform the user.
Addressing the Voice AI Infrastructure Gap
While many reference architectures focus solely on text-based agents, the demand for real-time voice AI is skyrocketing. Designing a production-ready AI agent infrastructure reference architecture must include prescriptive, voice-specific guidance—a critical gap missed by many generic AI platforms.
Processing voice introduces strict latency budgets. A natural human conversation requires response times of under 800 milliseconds. To achieve this, the architecture must abandon traditional REST APIs in favor of persistent, bidirectional connections such as WebSockets or WebRTC. The data flow becomes significantly more complex:
- Streaming Audio Ingestion: Audio must be streamed in chunks, utilizing Voice Activity Detection (VAD) algorithms at the edge to distinguish human speech from background noise, preventing unnecessary processing.
- Real-Time Speech-to-Text (STT): The audio chunks are piped into a highly optimized STT model. This model must support streaming inference to begin transcribing words before the user has even finished their sentence.
- Streaming LLM Inference: As the text is generated, it is fed incrementally into the reasoning engine. The engine must stream its output back immediately, often utilizing specialized smaller language models for faster time-to-first-token (TTFT).
- Text-to-Speech (TTS) Synthesis: The generated text is simultaneously pushed to a TTS engine, which streams the synthesized audio back to the user's device.
Optimizing this pipeline requires specialized MLOps tooling, advanced caching strategies for common phonetic responses, and utilizing hardware-accelerated endpoints. An enterprise-grade architecture will physically co-locate the STT, LLM, and TTS inference nodes within the same data center region to eliminate network transit latency.
Practical Implementation: Building an AI-Powered B2B Newsletter Writer
To contextualize this theoretical architecture, consider a community-contributed example project: an AI-powered B2B newsletter writer built utilizing the Alchemyst AI platform. This implementation highlights the practical application of the reference architecture components.
The newsletter agent requires deep context regarding the user's industry, past newsletter topics, and current market trends. The AI-Native Context Management layer securely retrieves the enterprise's historical content style guidelines and past publications. The Orchestration Engine divides the task: one sub-agent researches current B2B news utilizing customized web-scraping tools via the Secure Execution Environment, while another sub-agent drafts the content based on the gathered data. Throughout this process, the orchestration layer continuously validates the generated content against the retrieved enterprise context, ensuring high fidelity and brand consistency. Because the infrastructure natively handles state and connector management, developers can focus purely on refining the prompt engineering and content strategy, rather than wrestling with underlying server infrastructure.
Advanced MLOps Tooling for Agentic Workflows
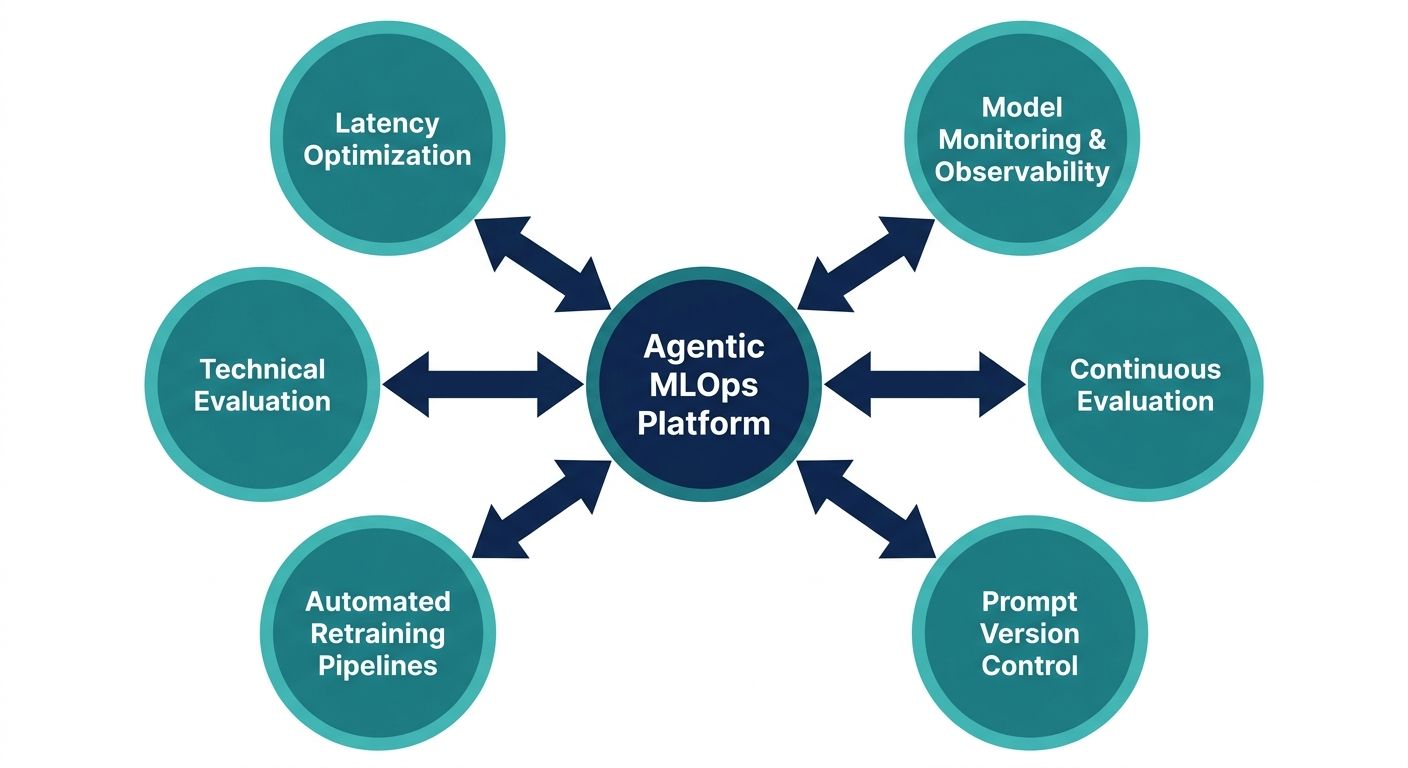
A production-ready AI agent infrastructure reference architecture is incomplete without a robust suite of Machine Learning Operations (MLOps) tooling. Operating autonomous agents in production requires unprecedented levels of observability, as the non-deterministic nature of LLMs means traditional software monitoring is insufficient.
Tracing and Observability: Engineering teams must be able to trace the "thought process" of the agent. This involves logging the exact prompt generated by the orchestrator, the context retrieved from the memory layer, the tools invoked, and the raw LLM response. Tools integrated into this layer must visualize these complex execution trees to help developers debug hallucination loops or tool execution failures rapidly.
Continuous Evaluation (Evals): Before deploying an update to an agent's prompt or underlying model, it must be evaluated against a baseline dataset. The architecture should include a continuous integration pipeline that runs automated "LLM Evals." These pipelines use larger, more capable models to grade the outputs of the production agent based on accuracy, tone, and adherence to constraints, ensuring that performance does not regress over time.
Dynamic Pricing and Cost Management: AI agents can quickly consume vast amounts of compute resources. A production environment requires built-in cost tracking per tenant or user. The architecture must dynamically monitor token usage, API calls, and storage constraints, linking them to billing services to support dynamic pricing models based on actual compute consumption.
Security, Compliance, and Enterprise Scalability
For large SMBs and enterprise-level organizations operating in heavily regulated sectors like finance or healthcare, the infrastructure must adhere to stringent security and compliance standards. Data sovereignty and privacy are paramount. The architecture should support deploying custom AI models within virtual private clouds (VPCs) to ensure that sensitive customer data never traverses public networks.
Furthermore, robust Role-Based Access Control (RBAC) must be implemented not just at the application level, but deeply integrated into the AI-Native Context Management layer. When an agent queries the vector database, it must only retrieve documents and context that the specific user has authorization to view. This prevents "context leakage," where an agent inadvertently summarizes restricted internal documents and presents them to unauthorized personnel.
Scalability in this architecture is achieved through containerization and Kubernetes orchestration. As traffic spikes—such as during a marketing campaign launch utilizing AI-driven content generation—the infrastructure must auto-scale the reasoning engine worker nodes and read-replicas of the context database independently, ensuring zero downtime and maintaining strict latency service level agreements (SLAs).
Conclusion
Transitioning from a promising local demo to a highly reliable, globally scalable AI deployment requires a fundamental shift in engineering strategy. By adhering to a rigorous production-ready AI agent infrastructure reference architecture, organizations can systematically dismantle the barriers to scale. Implementing dedicated layers for orchestration, secure tool execution, and voice-specific real-time processing ensures that agents perform reliably under load. Most importantly, integrating an AI-Native Context Management platform—such as Alchemyst AI—guarantees that these intelligent systems maintain deep, persistent, and secure memory, transforming them from mere conversational novelties into powerful, mission-critical enterprise assets.




