
The Critical Role of Context Handling in Enterprise AI Voice Agents
When enterprise leaders seek to compare enterprise AI voice agent platforms context handling capabilities, they are often met with superficial marketing collateral. The reality of deploying artificial intelligence in commercial voice environments requires a sophisticated understanding of how systems retain, process, and retrieve conversational memory. Context handling is the foundational architecture that determines whether an AI voice agent sounds like a disjointed automated system or a highly intelligent, empathetic human representative. In enterprise environments, voice agents handle unstructured, real-time data streams characterized by interruptions, non-linear conversational shifts, and complex multi-intent utterances. Without a robust methodology for context retention, even the most advanced natural language generation models will hallucinate, repeat themselves, or force users to restate previous points, ultimately destroying the customer experience and undermining operational efficiency.
Why Generic Voice AI Comparisons Fail Enterprise Users
A significant gap exists in the current market analysis of voice AI solutions. If you search for comparative analyses of platforms like Vapi.ai, Vellum, or Retell AI, the top results are almost exclusively generic listicles. These guides superficially cover surface-level features, integrations, and pricing tiers, completely failing to provide a direct, in-depth, and technical analysis of context handling capabilities specifically designed for voice AI agent platforms. Enterprise users do not need another list of basic API endpoints; they need comprehensive evaluations of the types of context handled, the underlying methodologies for retention, memory duration constraints, and voice-specific architectural requirements such as instantaneous Speech-to-Text (STT) and Text-to-Speech (TTS) integration. When an enterprise evaluates these platforms, the lack of quantifiable performance metrics in standard reviews leaves them vulnerable to selecting software that scales poorly under complex conversational loads. This deep dive aims to bridge that gap by ranking and analyzing platforms based on their context handling mastery.
Core Dimensions of Context Handling in Voice Architecture
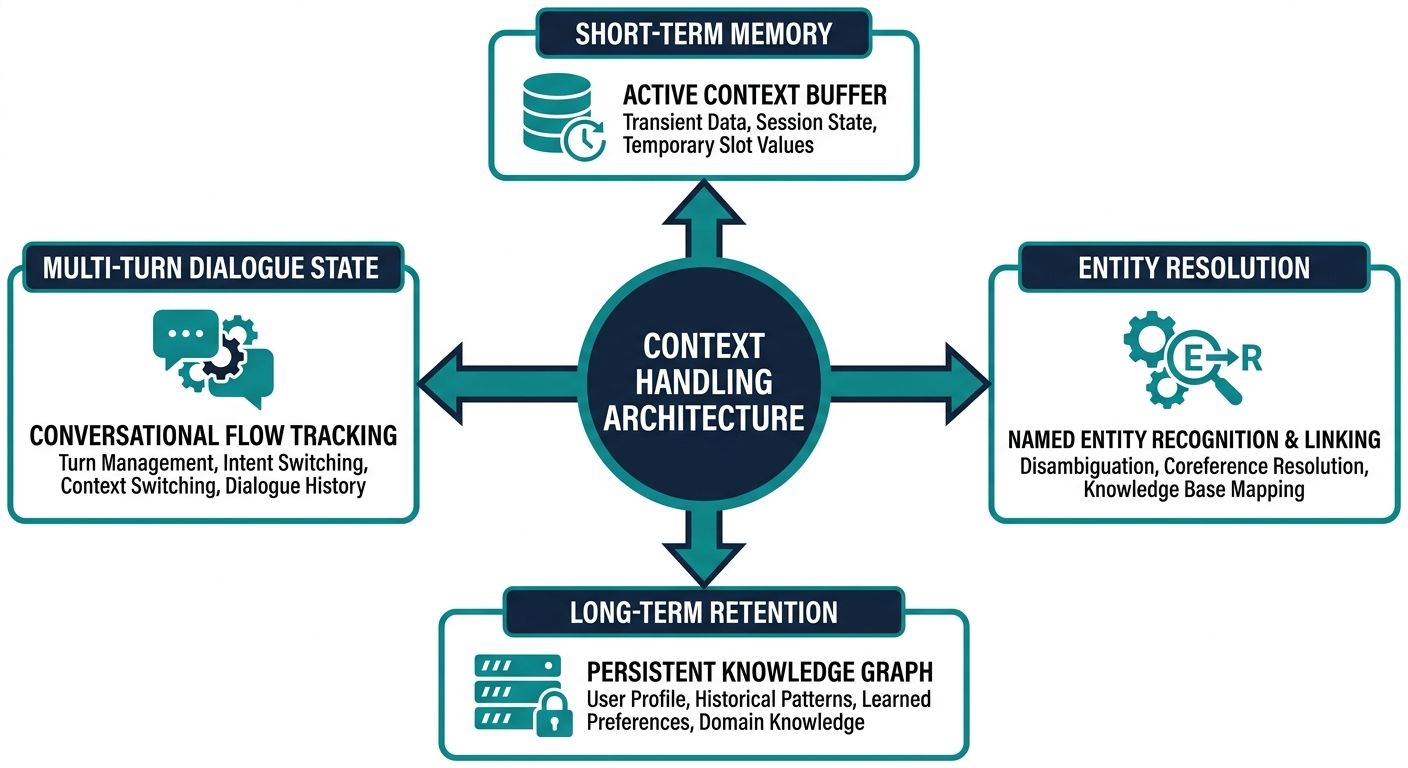
To truly compare enterprise AI voice agent platforms context handling, we must first break down the architectural dimensions that define advanced conversational memory. Voice agents do not operate like text-based chatbots; they are constrained by the speed of human speech and the acoustic complexities of live audio.
Multi-Turn Conversation Memory Retention
The ability to remember what was said three, ten, or fifty turns ago in a conversation is paramount. Enterprises must evaluate whether a platform uses a simple sliding token window, which inevitably forgets earlier context as the conversation progresses, or a more advanced semantic memory architecture. High-performance voice agents utilize a combination of short-term episodic memory for immediate dialogue resolution and long-term semantic memory, often powered by vector databases, to recall critical entities across a prolonged engagement.
Latency Mitigation in STT and TTS Integration
Context handling in voice AI is uniquely tied to latency. When a user speaks, the audio is processed by an STT engine, analyzed for context, passed to a large language model (LLM) for response generation, and synthesized back into audio via a TTS engine. If the context retrieval process is bloated or inefficient, the system introduces unnatural pauses. Leading platforms optimize this pipeline by pre-fetching contextual data during the user's speech phase and utilizing predictive contextual caching, allowing the TTS engine to begin streaming the response milliseconds after the user finishes speaking.
Handling Interruptions and Barge-ins
Human conversation is inherently messy. Users interrupt, change their minds mid-sentence, and refer back to previous topics abruptly. A critical dimension of context handling is how the system processes barge-ins. When a user interrupts the AI, the platform must instantaneously halt its TTS output, update its conversational state, integrate the new interrupted context with the historical context, and generate a revised response. Platforms that lack sophisticated context management will either ignore the interruption entirely or lose the thread of the conversation, resulting in catastrophic user frustration.
Comparing Technical Methodologies for Context Retention
Enterprise platforms utilize varying technical methodologies to maintain context during complex voice interactions. Understanding these approaches is crucial when determining the right infrastructure for sophisticated business needs.
Token Window Maximization vs. Dynamic Summarization
Basic platforms rely on feeding the entire conversation transcript back into the LLM's token window for every turn. While this works for short interactions, enterprise workflows quickly exceed token limits, leading to latency spikes and context degradation. Advanced platforms employ continuous dynamic summarization. In this methodology, the system operates parallel AI models that continuously summarize older portions of the transcript into dense, high-value contextual metadata. This metadata is retained in the active memory footprint, allowing the primary conversational model to reference historical facts without the computational burden of processing the raw transcript repeatedly.
Retrieval-Augmented Generation (RAG) in Voice Space
RAG has become standard in text AI, but applying it to real-time voice agents is technically demanding. When users ask questions requiring external enterprise knowledge, the voice agent must retrieve this information instantaneously. The methodology for context retention here involves embedding user queries in real-time, performing similarity searches across enterprise knowledge bases, and injecting that retrieved context into the prompt without causing conversational lag. The best enterprise platforms utilize specialized, lightweight embedding models specifically tuned for conversational queries to achieve sub-second retrieval times.
Evaluating the Competitor Landscape: Vapi, Retell, and Vellum
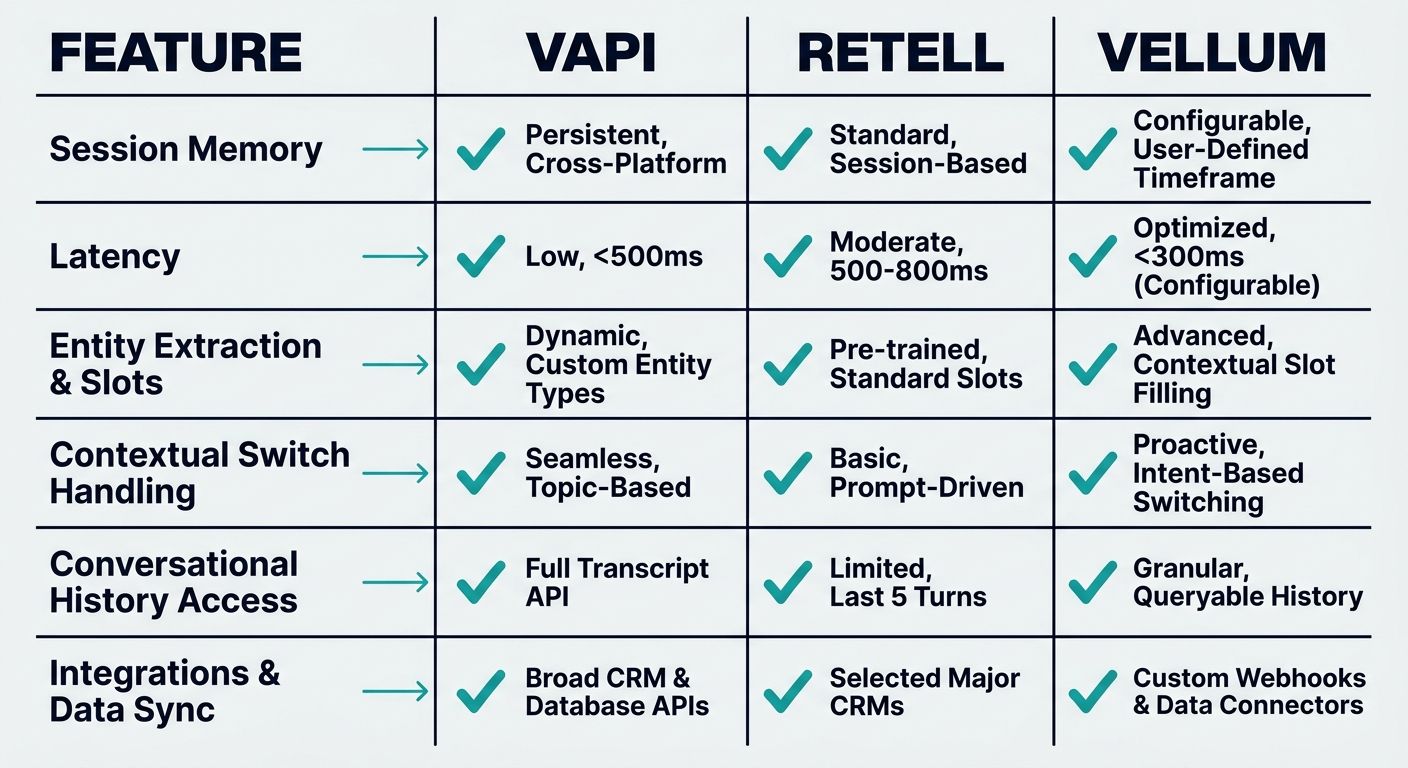
When assessing the current landscape, it becomes evident that many popular platforms prioritize developer flexibility over deep, out-of-the-box context mastery. Let us examine the technical gaps and capabilities of the leading competitors.
Vapi.ai: Developer-Centric Infrastructure
Vapi.ai has established itself by providing a highly configurable API for developers to build custom voice AI agents. They emphasize technical infrastructure, robust developer community resources, and open dashboard access for managing agents. However, Vapi primarily shifts the burden of context management onto the developer. While they provide the pipes for STT and TTS routing, enterprises are often left to build their own custom memory retention methodologies, state machines, and context-caching solutions. For businesses needing sophisticated, out-of-the-box context handling for intricate workflows, this purely infrastructural approach can lead to prolonged deployment cycles and high technical debt.
Retell AI and Vellum: Feature Breadth Over Deep Context
Platforms like Retell AI and Vellum offer excellent tools for prompt management and basic voice agent orchestration. However, when subjected to rigorous commercial investigation, they frequently reveal gaps in handling deep, non-linear context. Their architectures are often optimized for straightforward transactional calls rather than complex, consultative conversations. They lack deep technical methodologies for inter-session memory duration, meaning that if a user calls back a week later, the agent struggles to natively retrieve the acoustic and semantic context of the previous interaction without extensive custom engineering connecting them to external CRM databases.
Alchemyst AI: The AI-Native Context Management Advantage
In contrast to platforms that merely route audio to text models, Alchemyst AI positions itself as an AI-Native Context Management solution specifically engineered for the complexities of enterprise environments. This architectural distinction fundamentally changes how context is handled across audio processing and content generation workflows.
Proprietary Context Handling for Complex Workflows
Alchemyst AI provides a deep, proprietary approach to context retention that outpaces traditional API wrappers. By treating context management as a core platform service rather than an afterthought, Alchemyst ensures that real-time personalization and intelligent task automation are seamlessly integrated. The platform excels at intra-session and inter-session memory duration, utilizing advanced entity resolution to remember critical user details without continuous reprompting. This is particularly vital for sectors like e-commerce, finance, and healthcare, where maintaining an accurate contextual state across multiple touchpoints is a regulatory and operational necessity.
Enterprise Architecture and Custom Connectors
Unlike generic platforms, Alchemyst AI offers custom AI models tailored to specific enterprise vocabularies and acoustic environments. Their platform features custom connectors that seamlessly bind the voice agent's real-time conversational memory to secure, on-premise or cloud-based enterprise databases. This allows the AI to execute dynamic pricing discussions, predictive analytics, and complex business logic mid-conversation. Furthermore, Alchemyst's documentation, structured on the Mintlify framework using MDX, provides technical teams with practical, actionable depth for structuring and validating complex conversational flows, empowering developers to deploy sophisticated AI-powered B2B content generation and summarization tools.
Scalability from Free Tiers to Enterprise Deployment
Alchemyst AI structures its offerings to allow organizations to scale their context handling capabilities gracefully. From Forever Free to Pro and Enterprise plans, the platform scales monthly transcription limits, storage, and language support alongside its advanced AI summarization capabilities. This tiered approach allows small teams to leverage powerful audio processing while giving large enterprises access to dedicated support, robust security options, and the uncompromised computational power required for maintaining complex context across thousands of concurrent voice sessions.
Key Metrics for Comparing Context Handling Performance
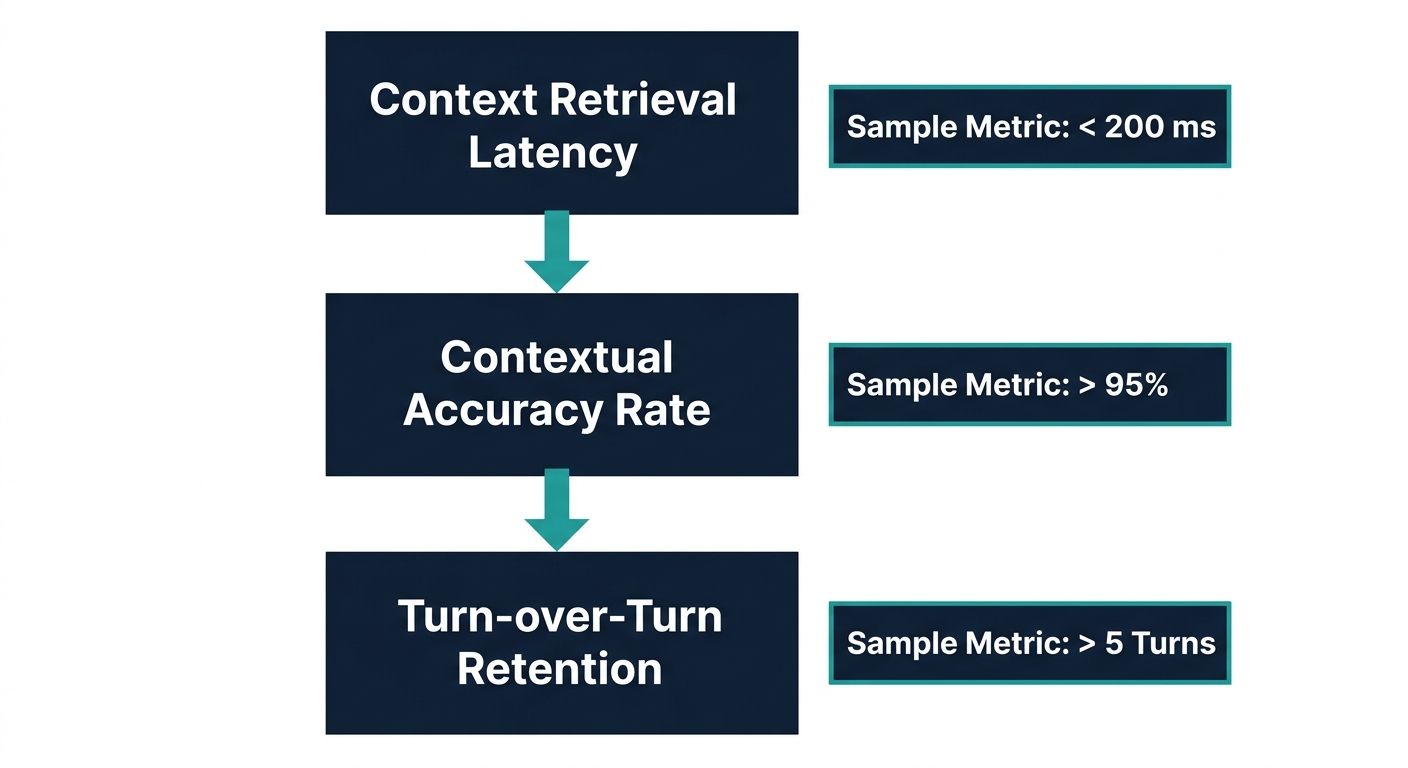
When executing a commercial evaluation of these platforms, enterprises must look beyond the marketing terminology and demand hard, quantifiable metrics. Here are the critical performance indicators that define true context handling mastery:
- Context Window Degradation Rate: This metric measures how frequently the AI hallucinates or forgets information after exceeding a specific threshold of conversational turns (e.g., 20, 50, or 100 turns). Superior platforms maintain near-zero degradation through dynamic summarization.
- Barge-in Recovery Latency: When a user interrupts the AI, this metric tracks the millisecond delay before the AI processes the new context and begins generating an updated, contextually accurate response. Acceptable enterprise standards require recovery in under 500 milliseconds.
- Entity Resolution Accuracy: In audio processing, STT engines often misspell names or industry-specific terms. This metric evaluates the system's ability to use historical conversational context to correct transcription errors dynamically before they corrupt the LLM's prompt.
- Inter-session Context Retrieval Time: For returning users, this metric measures the speed at which the platform can query historical databases, retrieve the context of past interactions, and inject it into the live session without causing initial greeting latency.
How to Choose the Right AI Voice Agent Platform for Your Enterprise
Selecting the optimal enterprise AI voice agent platform requires aligning your technical capabilities with your business objectives. If your organization boasts a massive engineering team dedicated to building custom state machines, a configurable API-first solution might suffice. However, if your goal is rapid deployment of highly intelligent, context-aware agents capable of driving business efficiency, task automation, and insightful analytics, you must prioritize platforms built around native context management.
Evaluate platforms based on their ability to handle real-world acoustic chaos. Ask vendors to demonstrate multi-turn conversations featuring heavy interruptions, abrupt topic changes, and callbacks to early conversational statements. Demand visibility into their transcription pipelines and ask specifically about their methodologies for mitigating token exhaustion during long interactions. An enterprise platform must not only transcribe speech; it must comprehend, retain, and intelligently leverage the underlying meaning of that speech across the entire customer lifecycle.
Conclusion: Mastering Context for Next-Generation Voice AI
The enterprise landscape is rapidly moving past rudimentary voice bots towards sophisticated, AI-driven conversational agents. To compare enterprise AI voice agent platforms context handling capabilities effectively, decision-makers must pierce through the noise of generic listicles and demand rigorous architectural analysis. While competitors focus on providing developer APIs or broad orchestration features, the true differentiator in the market is the mastery of conversational memory. By prioritizing advanced context retention methodologies, minimizing latency in STT/TTS pipelines, and demanding robust, quantifiable performance metrics, enterprises can select powerful solutions like Alchemyst AI that genuinely transform business operations, customer service, and growth trajectories.




