
The Paradigm Shift in Enterprise Voice Operations
Finding the best multilingual AI voice OS for high volume customer service requires moving beyond superficial feature lists and basic chatbot integrations. In today's highly demanding enterprise landscape, global organizations are confronted with a significant challenge: how to seamlessly manage tens of thousands of concurrent voice interactions across dozens of languages without compromising on contextual accuracy, latency, or customer satisfaction. Legacy conversational AI platforms and basic API wrappers are inherently flawed when exposed to high-volume interactions. They rely heavily on outdated keyword matching, delayed translation APIs, and rigid conversational trees that break down the moment a customer introduces a complex, multi-layered inquiry.
Technical evaluators and developers recognize that the solution does not lie in better prompt engineering, but in robust context engineering. An enterprise-grade AI Voice Operating System (OS) must possess an underlying architectural framework capable of dynamic information retrieval, real-time CRM integration, and context arithmetic. This technical primer explores the definitive blueprint for selecting, integrating, and calculating the return on investment (ROI) for advanced voice AI platforms, with a specific focus on the capabilities of Alchemyst's Kathan engine.
Overcoming the Limitations of Superficial AI Platforms
If you analyze the current market offerings for multilingual AI agents, you will find an abundance of platforms promoting highly configurable tools, rapid deployments, and basic API-first approaches. However, a glaring content gap exists in the industry's understanding of what constitutes an actual AI Voice OS. Competitors often highlight their proof by numbers or superficial language translation capabilities. What they consistently miss is the architectural, technical, and operational depth required to deploy a true OS tailored for high-volume enterprise customer service.
Standard voice AI systems attempt to handle multilingual queries by routing speech through isolated transcription, translation, and text-generation microservices. This disconnected approach introduces severe latency and strips away the semantic nuance essential for effective customer support. When a customer speaks in a blend of colloquial phrases and technical jargon, a rudimentary platform will either hallucinate an answer or fall back to human routing. To genuinely achieve the status of the best multilingual AI voice OS for high volume customer service, a platform must integrate a unified context layer that mathematically processes metadata and contextual relevance in real time.
Core Architecture: Prompt Engineering vs. Context Engineering
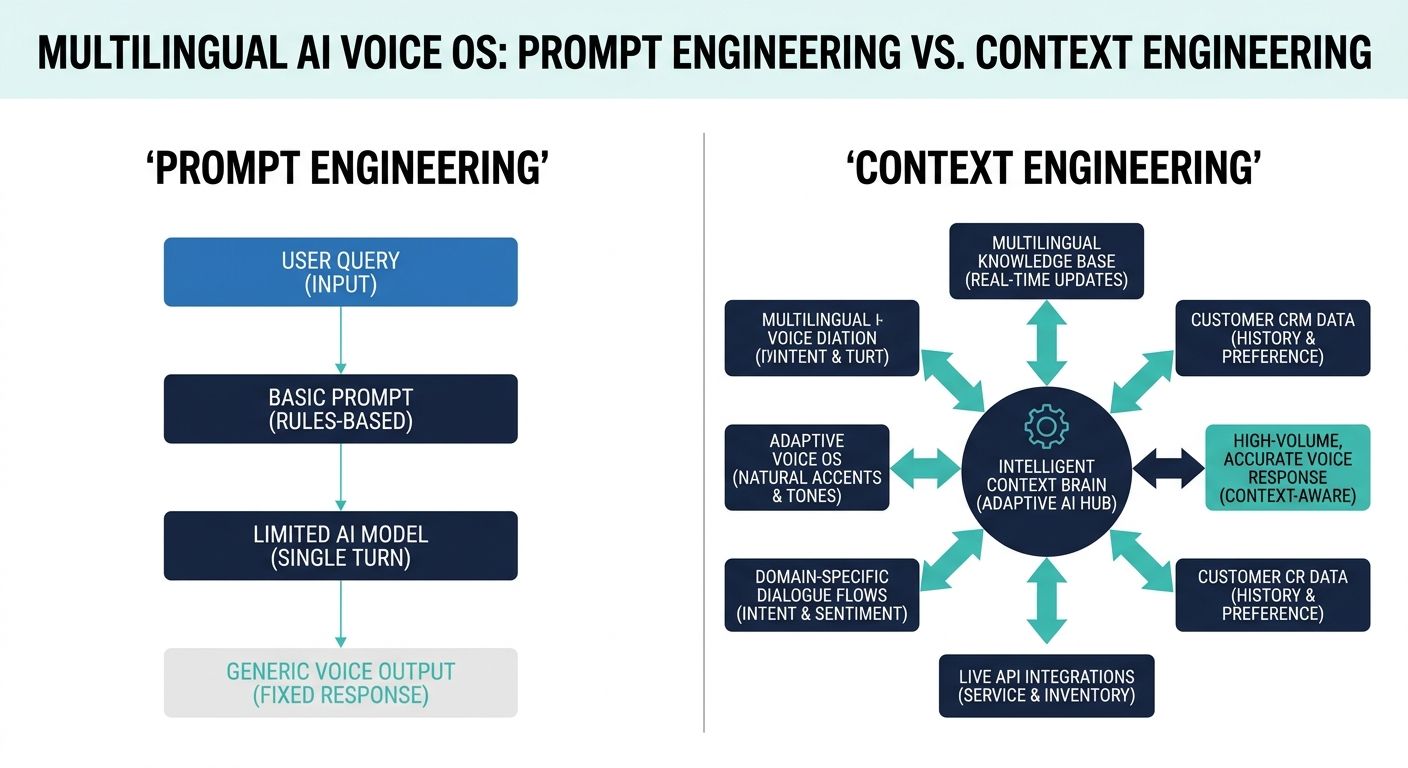
To understand the mechanics of an elite AI Voice OS, one must differentiate between prompt engineering and context engineering. Prompt engineering involves tweaking the textual instructions fed to a large language model (LLM) in hopes of guiding its tone and behavior. While necessary, it is highly insufficient for complex enterprise applications. You cannot prompt your way out of missing data.
Context engineering, on the other hand, is the structural science of dynamically fetching, structuring, and feeding the exact required knowledge to the voice agent in milliseconds. This is the realm where Alchemyst's Kathan engine dominates. By prioritizing context engineering, the Kathan engine ensures that the AI does not merely guess the answer based on its broad training data, but strictly computes the answer based on real-time enterprise data, specific customer history, and exact product specifications—regardless of the language being spoken.
Deep Dive: The Context Arithmetic Pipeline
The Kathan engine utilizes a proprietary methodology known as context arithmetic. This is not a buzzword; it is a rigorous computational process designed to systematically determine the precise information relevant to any given voice interaction. For technical evaluators looking for the best multilingual AI voice OS for high volume customer service, understanding this five-stage pipeline is critical.
1. Semantic Similarity Search
At the core of the Kathan engine's information retrieval system is advanced semantic similarity search. Instead of looking for exact word matches, the system vectorizes enterprise knowledge bases and customer histories into high-dimensional mathematical spaces. When a user speaks, their utterance is instantly embedded and matched against these vectors. This is particularly crucial for multilingual support, as the semantic meaning of a query remains mathematically consistent even if the spoken language changes, allowing the OS to fetch relevant context across language barriers without heavy reliance on literal translations.
2. Granular Metadata Filtering
High-volume customer service means dealing with vast, often contradictory, datasets. Metadata filtering allows the OS to immediately discard irrelevant information based on strict parameters such as the user's geographic location, account tier, or active product version. If a French-speaking enterprise client asks about a specific API rate limit, the metadata filter ensures the system only searches within the enterprise-tier documentation, drastically reducing the search space and computing time.
3. Rigorous Deduplication Mechanisms
Enterprise datasets are notorious for redundancy. Multiple documents might address the same troubleshooting steps. The deduplication stage in the context arithmetic pipeline ensures that the AI agent is not overwhelmed with repetitive data blocks. By mathematically identifying and merging overlapping vectors, the Kathan engine keeps the context window lean, reducing latency and preventing the LLM from becoming confused by conflicting phrasing of the same solution.
4. Dynamic Ranking Protocols
Once relevant, non-duplicated information is retrieved, it must be ranked. Dynamic ranking protocols assign a relevance score to each piece of data based on the real-time progression of the conversation. In a high-volume scenario where a customer might pivot from billing issues to technical troubleshooting within the same breath, the ranking protocol instantly reshuffles the priority of the retrieved context, ensuring the AI agent always addresses the most immediate intent first.
5. The Set-Algebraic Pipeline Assembly
The final stage is the set-algebraic pipeline assembly. The retrieved, filtered, deduplicated, and ranked data sets are combined using logical operations (unions, intersections, differences) to form a cohesive, perfectly structured context payload. This mathematically precise payload is then injected into the core generative model, enabling the AI voice agent to deliver a flawless, deeply informed response in the user's native language.
The Definitive Migration Blueprint: Implementing an AI Voice OS
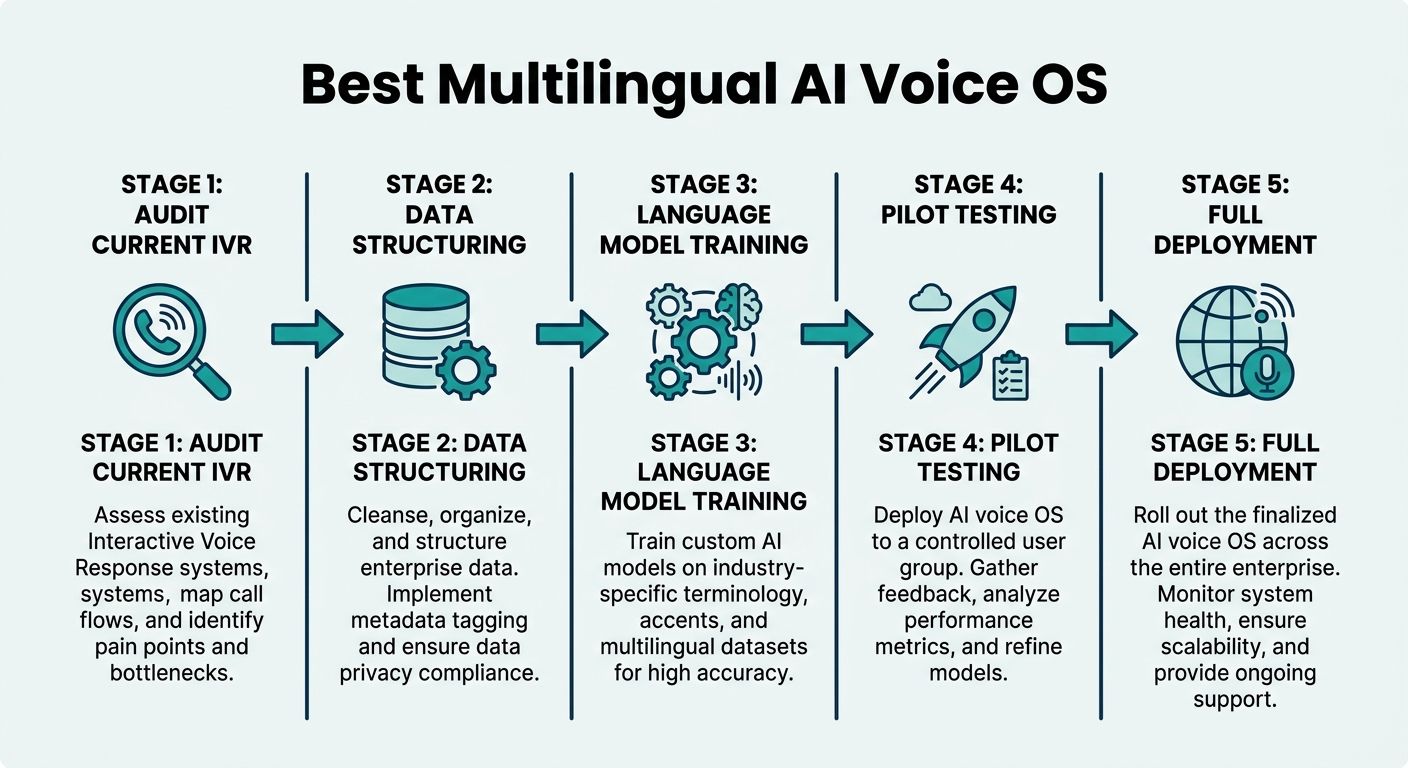
Recognizing the technological superiority of context-aware systems is only the first step. The true challenge for enterprise leaders is deployment. The lack of a comprehensive migration blueprint is a major failure point for generic AI platforms. Transitioning to the best multilingual AI voice OS for high volume customer service requires a structured, multi-phase approach tailored for complex technical environments.
Phase 1: Infrastructure and Legacy System Auditing
Before any software is deployed, a rigorous audit of existing infrastructure must take place. This involves mapping out current telephony systems (SIP trunks, PBX), legacy CRM databases, and existing knowledge repositories. Developers must identify data silos and assess the API readiness of all interconnected tools. The goal of this phase is to establish the baseline concurrency limits and identify the specific multilingual routing rules currently handled by human agents.
Phase 2: Technical Integration and Real-Time CRM Data Sync
The hallmark of an AI Voice OS is its deep integration capabilities. During this phase, engineering teams establish secure Webhook and WebSocket connections between the AI OS and enterprise databases. Real-time CRM data integration ensures that the moment a call is connected, the AI agent is instantly populated with the caller's entire historical context. This phase also involves deploying the context arithmetic engine locally or within a dedicated virtual private cloud to ensure data sovereignty and ultra-low latency data syncs.
Phase 3: Data Migration and Enterprise-Grade Security
Migrating enterprise data to feed the semantic search vectors requires careful sanitization. Sensitive Personally Identifiable Information (PII) and Payment Card Industry (PCI) data must be encrypted or tokenized before it ever touches the context layer. The migration blueprint mandates the setup of strict role-based access controls and the implementation of real-time redaction protocols, ensuring that the AI voice agent operates strictly within global compliance frameworks, such as GDPR and SOC2.
Phase 4: Rigorous Multilingual Tuning and Quality Assurance
Language is highly localized. Spanish in Spain differs significantly from Spanish in Mexico. The tuning phase involves exposing the AI Voice OS to hundreds of thousands of historical conversational transcripts to map regional dialects, colloquialisms, and brand-specific jargon across all supported languages. Quality Assurance teams execute load testing, simulating thousands of concurrent calls to validate the performance of the context algebraic pipeline under maximum enterprise stress.
Structured ROI Framework and Cost Analysis
Many competitor platforms offer generic cost savings calculators based entirely on headcount reduction. However, a technical evaluator assessing the best multilingual AI voice OS for high volume customer service demands a far more structured ROI framework that encompasses operational resilience and contextual efficiency.
Calculating Context-Aware Deflection Rates
Traditional metrics look at basic call deflection. Advanced ROI calculations focus on context-aware deflection. This measures the percentage of highly complex, multi-turn interactions successfully resolved by the AI without human intervention. By utilizing the Kathan engine's dynamic ranking and metadata filtering, enterprises see a massive increase in context-aware deflection. ROI is calculated by measuring the drop in average handle time (AHT) for these complex queries multiplied by the loaded cost of a tier-2 human support agent.
Precision Concurrency Metrics and Scaling
A true AI Voice OS scales non-linearly. Unlike human call centers where doubling capacity requires doubling the workforce, an AI OS can instantly scale to meet unexpected volume spikes. The financial model must calculate the savings achieved by eliminating over-staffing requirements during seasonal peaks or critical service outages. Furthermore, the ability to serve a global customer base without setting up redundant regional call centers yields immense savings in physical real estate, localized hiring, and cross-border telecommunications costs.
Concrete Industry-Focused Use Cases
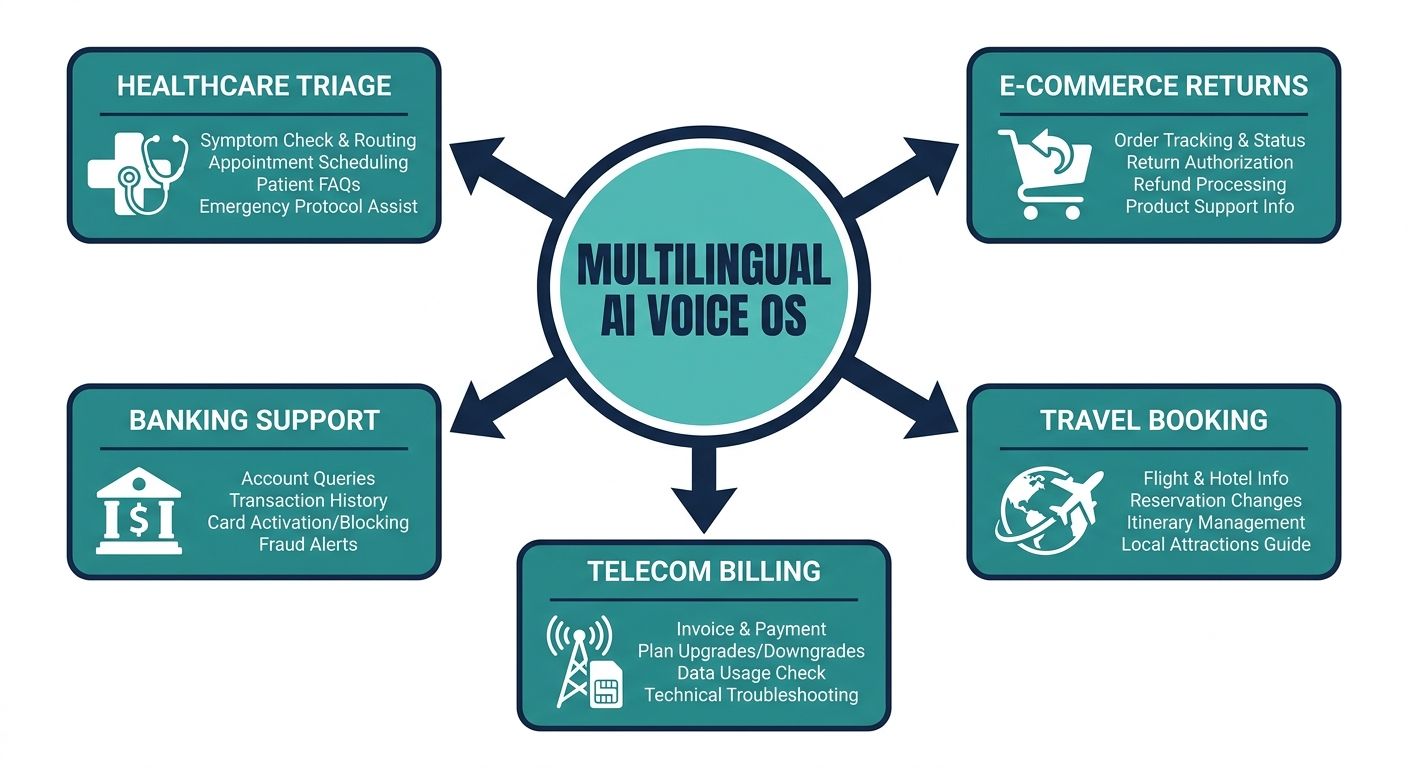
The theoretical architecture of context arithmetic proves its worth when applied to specific, high-stakes enterprise environments.
Telecommunications Support
Telecom companies face massive inquiry volumes regarding billing errors, network outages, and device troubleshooting. A multilingual AI voice OS can instantly ingest real-time network status metadata and cross-reference it with a user's geographical location. If a localized outage occurs in a diverse urban area, the AI can preemptively notify callers of the exact issue in their preferred language, drastically reducing queue times and mitigating customer frustration during critical downtime events.
Global Financial Services
In the banking sector, context is not just helpful; it is legally required. When a customer calls regarding a frozen credit card while traveling abroad, the AI agent must flawlessly navigate security authentication, retrieve highly sensitive transaction metadata, and communicate the resolution in multiple languages. The rigorous deduplication and set-algebraic pipeline of the AI Voice OS ensures that the agent never hallucinated financial data, maintaining strict regulatory compliance while resolving the issue instantaneously.
Evaluating Competitors vs. True Voice Operating Systems
When comparing top-ranking platforms, it becomes evident why simple chatbots fail the enterprise test. Competitors focus heavily on providing a developer community and open dashboard access for custom agents, heavily marketing API-first programmability. While modularity is useful, relying solely on API calls to external language models creates a brittle architecture that collapses under high-volume stress.
An enterprise seeking the best multilingual AI voice OS for high volume customer service must look beyond the wrapper. They require a dedicated engine, like Kathan, that treats conversational context as a mathematical certainty rather than a probabilistic guess. By controlling the information retrieval, vector search, and payload injection natively, a true Voice OS eliminates the latency and inaccuracy that plague disjointed platform architectures.
Conclusion
Adopting the best multilingual AI voice OS for high volume customer service is a massive strategic initiative that redefines how an enterprise engages with its global audience. It requires discarding outdated legacy tools and superficial chatbot solutions in favor of a mathematically rigorous, context-aware architecture. By leveraging the principles of context arithmetic, implementing a meticulously structured migration blueprint, and measuring true operational ROI, enterprises can deploy a voice AI system that is not merely conversational, but fundamentally intelligent. Platforms equipped with engines like Kathan stand ready to support this paradigm shift, offering unparalleled scale, security, and multilingual precision for the future of global customer operations.




