
The Need for Actionable AI Context Engine API Documentation
The transition toward context-aware artificial intelligence has fundamentally altered the landscape of software engineering. Modern applications, particularly complex Voice OS platforms, demand dynamic access to real-time information to function effectively. However, when software engineers search for integration guides, the available resources consistently fall short. Most top-ranking materials offer conceptual thought leadership regarding context engineering, discussing why Large Language Models require context, rather than providing the transactional, hands-on resources that engineering teams actively seek.
Developers do not merely need theoretical essays on the importance of contextual data; they require specific, transactional AI context engine API documentation for developers. They need to understand exactly how to structure their HTTP requests, which authentication methods are mandated, how to properly format complex JSON payloads, and how to programmatically parse algorithmic responses. This definitive reference guide fills that exact gap in the developer ecosystem. By focusing on Alchemyst's proprietary Kathan engine, this documentation moves past high-level fluff to deliver a concrete, step-by-step blueprint for building a real-world, contextually aware AI system.
Architectural Foundation: Context Arithmetic and The Kathan Engine
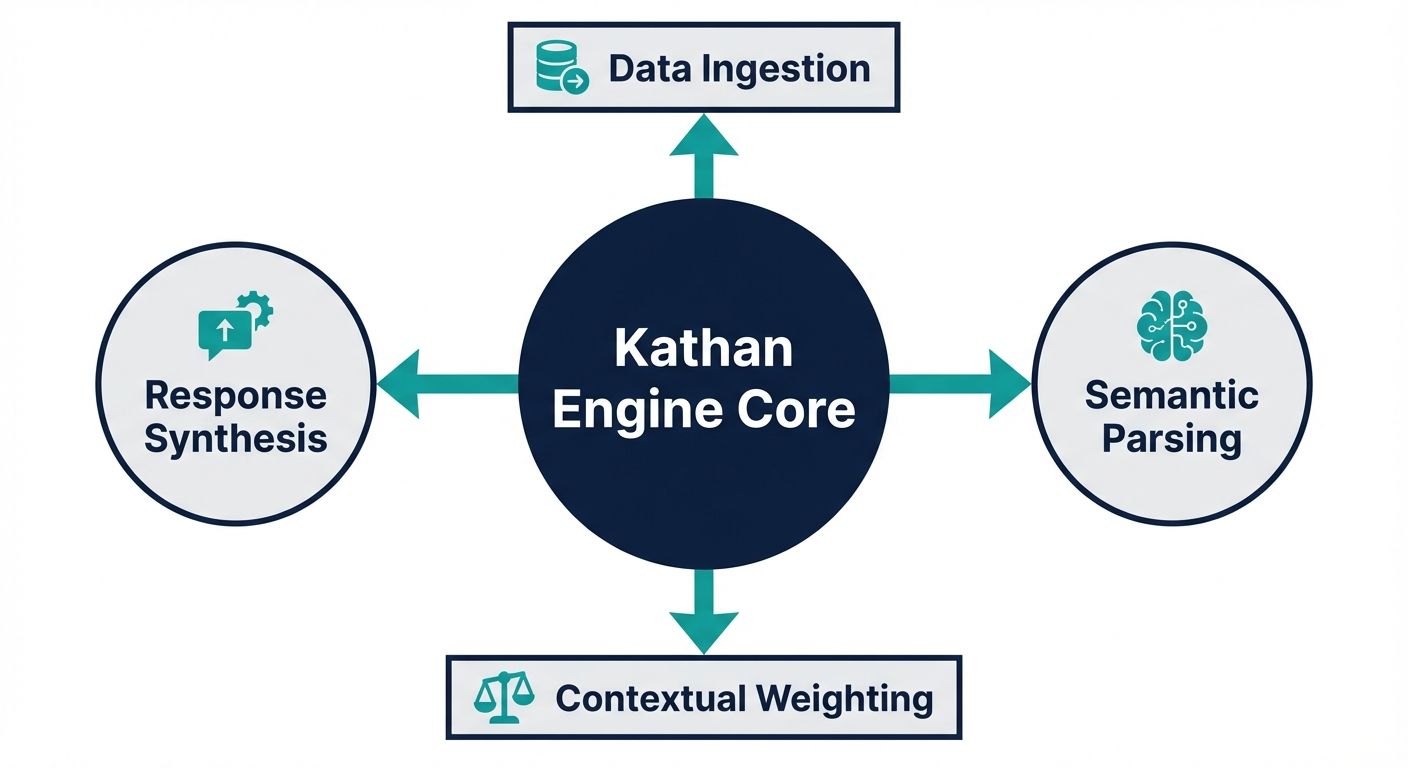
Before writing a single line of code to interact with the API, it is absolutely essential to understand the underlying architectural philosophy of the system. The Kathan engine distinguishes itself through a systematic, computational process known as Context Arithmetic. For developers building sophisticated voice agents, Context Arithmetic functions as a highly structured, set-algebraic pipeline. It programmatically determines the most relevant vectors of information to inject into an AI's prompt at any given millisecond.
Unlike legacy, context-free agents that blindly pull massive, unstructured chunks of data from a vector database—often leading to prompt overflow and severe latency—the Kathan engine filters, computes, and intersects precise data points. This pipeline consists of a rigorous five-stage information retrieval process that ensures high fidelity and minimal token consumption.
Stage 1: High-Dimensional Semantic Search
The first stage of the API's backend process involves mapping the end-user's natural language query into a high-dimensional vector space. When a request hits the computation endpoint, the engine executes a rapid semantic similarity search against the pre-indexed data. This ensures that the engine retrieves documents based on intent and contextual meaning, rather than relying on brittle keyword matching algorithms.
Stage 2: Rigorous Metadata Filtering
Semantic search alone is insufficient for enterprise applications. The second stage applies strict boolean metadata filtering. Developers can pass custom parameters via the API to constrain the context by specific timestamps, unique user identifiers, or stringent Role-Based Access Controls. If a document matches the semantic intent but violates the metadata access policy, the engine mathematically excludes it from the context pool.
Stage 3: Mathematical Deduplication
Redundancy is a major issue when feeding data to Large Language Models. Stage three introduces the deduplication phase. Here, the Context Arithmetic pipeline identifies overlapping informational vectors and algorithmically strips away redundant contextual data. This ensures that the AI receives a lean, diverse set of facts, optimizing the token usage and drastically reducing computational costs.
Stage 4: Confidence Ranking
Not all retrieved context is equally valuable. In stage four, the engine handles ranking and scoring. Every piece of contextual data is evaluated and assigned a confidence score based on its relevance to the specific user query and its recency. Developers can configure acceptable confidence thresholds within their API requests, dropping low-quality data before it reaches the voice agent.
Stage 5: Dynamic Prompt Injection
The final stage is the synthesis of the retrieved data. The engine dynamically structures the heavily filtered, ranked, and deduplicated context into a cohesive string. This finalized context is what the API returns to the developer, ready to be prepended to the active memory prompt of the voice OS.
Core API Configuration and Authentication
To interact with the context engine seamlessly, developers must configure their environments to authenticate every request securely. The API adheres to strict RESTful design principles, demanding secure token exchange and standardized headers.
- Base API URL: All endpoints are structured under the secure base routing.
- Authentication Mechanism: The API requires a persistent Bearer Token passed via the Authorization header on every single request.
- Content Types: The engine exclusively accepts and returns JSON payloads. The Content-Type header must strictly be application/json.
- Rate Limiting and Quotas: To maintain system stability during intense Voice OS traffic, the API enforces a limit of one thousand requests per minute per authenticated developer account. Exceeding this triggers a standard timeout response.
AI Context Engine API Documentation for Developers: Core Endpoints
This section provides the actionable AI context engine API documentation for developers, outlining the precise schemas required to initialize sessions, push data into the pipeline, and compute contextual responses.
1. Initialize a Context Session
Every contextual interaction must occur within an isolated stateful environment. The initialization endpoint generates a temporary workspace where the Context Arithmetic pipeline can safely operate without data bleeding between disparate users.
Endpoint Route: POST /v1/context/session
Request Payload Schema:
- agent_id (string, required): The universally unique identifier assigned to your specific voice agent configuration.
- environment (string, optional): Defines the workspace context, typically designated as either production or staging.
- time_to_live (integer, optional): The exact duration in seconds that the session should remain active before the engine automatically purges the context pool. Defaults to 3600 seconds.
Response Payload Schema:
- session_id (string): The newly generated cryptographic UUID for the active session. This key must be appended to all subsequent integration requests.
- status (string): Confirmation string indicating the session is successfully initialized and ready for injection.
- expiration_timestamp (string): An ISO 8601 formatted timestamp detailing exactly when the session will be garbage collected.
2. Inject Context Data into the Pipeline
With an active session established, engineers must populate the engine with raw data. This injection endpoint feeds the foundational vector database, allowing the semantic search and metadata filtering stages to operate effectively. High-quality injection is critical for optimal Voice OS performance.
Endpoint Route: POST /v1/context/inject
Request Payload Schema:
- session_id (string, required): The active session UUID obtained from the initialization endpoint.
- documents (array, required): A JSON array containing the context objects to be embedded into the arithmetic engine.
- documents[].content (string, required): The raw textual data, such as a user CRM record, previous chat transcript, or internal knowledge base article.
- documents[].metadata (object, required): Key-value pairs utilized during Stage 2 filtering. Must include fields like document_type, creation_date, and authorization_level.
Response Payload Schema:
- documents_processed (integer): The total count of data chunks successfully vectorized and stored in the session memory.
- documents_failed (integer): Count of documents rejected due to malformed text or missing mandatory metadata fields.
- vector_references (array): Unique database pointers mapped to your injected documents for auditing purposes.
3. Execute Context Arithmetic Computation
This endpoint represents the heart of the Kathan engine. By invoking the compute route, developers trigger the complete five-stage algorithmic pipeline. The engine parses the user's query, executes the arithmetic deduplication, and returns the optimized string for the Language Model.
Endpoint Route: POST /v1/context/compute
Request Payload Schema:
- session_id (string, required): The active session UUID where the relevant documents reside.
- user_input (string, required): The exact transcription of the spoken query or typed text from the end-user.
- minimum_confidence (float, optional): A strict threshold ranging from 0.0 to 1.0. Context scored below this decimal will be aggressively dropped. The system default is set to 0.75.
- token_limit (integer, optional): A hard cap on the size of the returned context string to prevent prompt overflow.
Response Payload Schema:
- synthesized_context (string): The finalized, highly optimized textual string ready to be directly concatenated into your LLM's system prompt.
- source_citations (array): An array of metadata tags referencing exactly which injected documents survived the arithmetic pipeline to form the context.
- overall_confidence (float): The algorithmic certainty score of the returned context payload.
Comprehensive Error Handling and Status Codes
Robust enterprise integrations require resilient error handling. The API leverages standard HTTP status codes, accompanied by descriptive JSON error messages to streamline debugging.
- 400 Bad Request: Triggered when a request payload is malformed or lacks required fields, such as missing the agent_id during session initialization.
- 401 Unauthorized: Returned when the Bearer token is missing, expired, or cryptographically invalid.
- 403 Forbidden: Occurs when the authenticated developer account lacks the permissions to access a specified voice agent configuration.
- 429 Too Many Requests: Indicates the developer has breached the strict rate limit quota. The response headers will include a Retry-After value.
- 500 Internal Server Error: Signifies an unexpected failure within the computational pipeline. Developers should implement exponential backoff retry logic.
Developer Integration and Implementation Patterns
To maximize the utility of this AI context engine API documentation for developers, it is vital to conceptualize how these endpoints interconnect within various programming environments. Although actual code architectures vary, the asynchronous logic flow remains largely consistent across modern stacks.
Asynchronous Logic in Node Applications
In Node environments, engineers predominantly rely on asynchronous fetch implementations or libraries like Axios. The integration sequence involves awaiting the session initialization, extracting the UUID, and immediately firing the injection endpoint. Webhook listeners capture the user's voice transcription, map it to the compute payload, and await the synthesized context before routing the final prompt to the underlying language model. Concurrency is easily managed using standard Promise architecture.
Synchronous Pipelines in Python Environments
Python developers typically implement this API using the robust Requests library or asynchronous frameworks like FastAPI. Python is exceptionally well-suited for the injection phase. Engineers can leverage data manipulation libraries such as Pandas to clean, format, and structure massive datasets into perfect metadata schemas before batching requests to the API. Persistent session objects help maintain connection pools, significantly reducing latency during the compute phase.
High-Concurrency Connections in Go
For large-scale telecom or enterprise integrations demanding absolute minimal latency, Go is the language of choice. By defining strict structural types that map precisely to our JSON schemas, developers ensure type safety at compile time. Go routines allow development teams to parallelize the injection of multiple data sources simultaneously, populating the context engine's vector space in milliseconds before the user even finishes speaking their first sentence.
Best Practices for Managing Contextual Workloads
Successfully integrating an API is merely the baseline. Sustaining a high-performance, context-aware artificial intelligence requires strict adherence to data management best practices. The engine is only as intelligent as the data it processes.
Data freshness is arguably the most critical metric. Developers must proactively configure time-to-live parameters during session initialization. Allowing stale CRM data to linger in the context pool inevitably leads to AI hallucinations, where the Voice OS provides factually incorrect information based on outdated states. Implementing aggressive garbage collection on contextual sessions protects the end-user experience.
Security and privacy stripping must occur prior to the injection phase. When transmitting user profiles to the API, developers must programmatically strip Personally Identifiable Information unless that specific data point is strictly necessary for the transaction at hand. Utilizing the robust metadata system allows engineers to implement fine-grained access controls, ensuring that restricted internal documents are mathematically blocked from unauthorized user queries during Stage 2 of the arithmetic pipeline.
The ROI Framework: Cost Per Qualified Outcome
Implementing deep contextual integrations provides substantial, trackable financial advantages. Historically, Voice AI pricing strategies, especially in emerging markets, have obscured massive inefficiencies through arbitrary per-minute or per-seat billing models. These older, context-free systems often result in cyclical, redundant conversations, purposely inflating the duration of the call without actually resolving the customer's intent.
By integrating a highly efficient context pipeline, businesses can pivot to a superior analytical metric: the Cost Per Qualified Outcome. Because the arithmetic engine instantly deduplicates data and injects the exact necessary context into the prompt, the agent's time-to-resolution plummets. The AI understands the specific historical context immediately, resolving the issue on the very first attempt. Engineering teams can directly map API compute costs against successful ticket resolutions, providing stakeholders with a transparent, structured Return on Investment framework that exposes the hidden costs of legacy solutions.
The Definitive Blueprint for Voice OS Migration
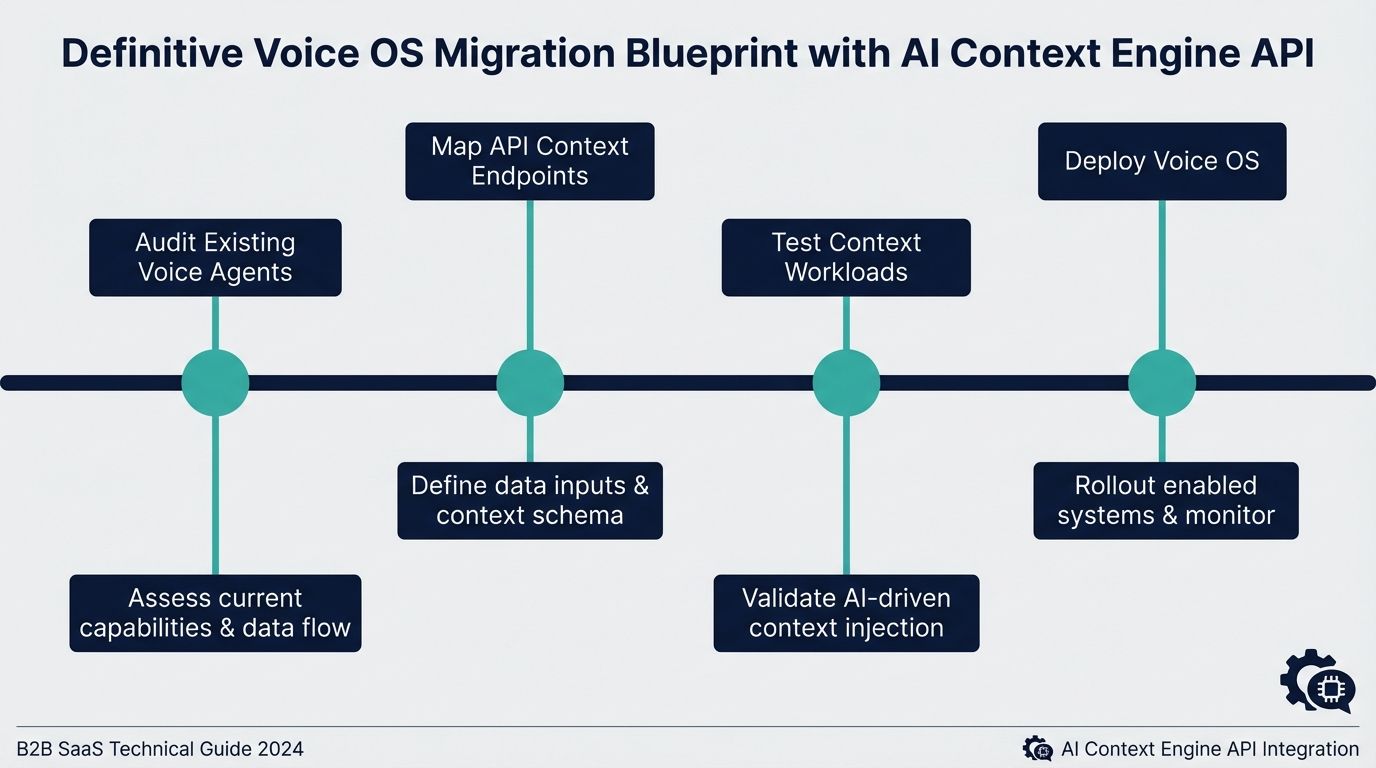
Transitioning from a legacy IVR or a standard chatbot to a fully context-aware Voice OS necessitates a methodical migration blueprint. Utilizing this AI context engine API documentation for developers simplifies the transition into four distinct engineering phases.
The first phase is the comprehensive data audit. Engineering teams must map out all disparate data silos—internal knowledge bases, user ticketing systems, and active CRM states. This audit defines what information needs to be actively injected into the context engine during a user session.
The second phase involves payload schema mapping. Developers must write the middleware logic that transforms their audited data into the strict JSON arrays required by the injection endpoint. This step focuses heavily on standardizing metadata tags so the retrieval pipeline can filter information cleanly.
The third phase is the prompt engineering overhaul. In legacy systems, developers often bloat the core system prompt with endless conditional instructions. During migration, these static prompts must be refactored into dynamic, lean templates. The templates simply contain a placeholder variable that accepts the synthesized string returned by the compute endpoint. This architectural shift massively reduces LLM token consumption per transaction.
The final phase is continuous Quality Assurance driven by algorithmic confidence. By logging the confidence scores returned in the computation response, developers can programmatically identify blind spots in their knowledge base. If specific user queries repeatedly yield low confidence scores, the engineering team knows exactly which domains require richer data injection.
Conclusion: Building the Next Generation of Voice Agents
The era of context-blind, frustrating automated systems is rapidly drawing to a close. To remain competitive, enterprises must adopt intelligent architectures capable of mathematical precision and dynamic reasoning. However, achieving this vision requires more than just high-level discussions; it demands concrete, developer-centric tools and uncompromising API specifications.
This comprehensive AI context engine API documentation for developers serves as the definitive bridge between advanced context engineering theory and practical software execution. By mastering session initialization, rigorously formatting injection payloads, and leveraging the full power of Context Arithmetic computations, engineering teams can build resilient systems. Leverage these endpoints, adhere to the outlined integration patterns, and successfully transition your infrastructure to a context-aware Voice OS that guarantees measurable outcomes and unprecedented user experiences.




