
The Illusion of the AI Demo vs. The Reality of Production
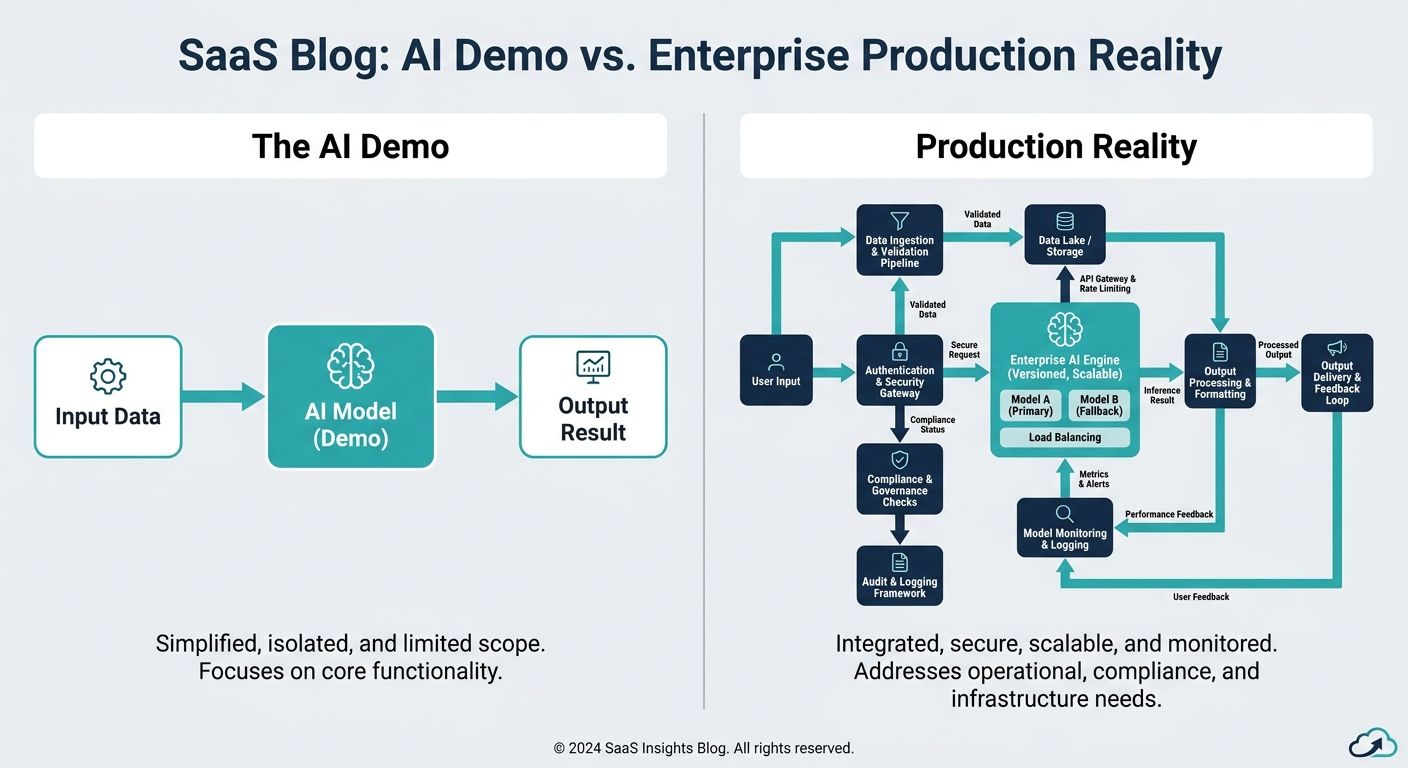
In the rapidly evolving landscape of artificial intelligence, a troubling pattern has emerged across enterprise IT: the demo-to-deployment gap. A proof-of-concept (POC) AI agent operates flawlessly in a controlled sandbox, answering predefined queries with astonishing speed and conversational fluidity. However, when tasked with navigating the unstructured, high-velocity environment of a live enterprise production system, the same agent crumbles. It hallucinates, loses conversational context, triggers exponential API costs, and ultimately fails to deliver business value.
Current industry discourse frequently identifies this gap but rarely offers prescriptive, actionable technical solutions. Transitioning an AI agent from a sleek demonstration to a robust, enterprise-grade deployment requires far more than basic API wrappers. It necessitates a paradigm shift in how we approach enterprise AI agent infrastructure, moving away from stateless, context-free models toward highly orchestrated, context-aware systems driven by rigorous MLOps and advanced information retrieval architectures.
Why Context-Free Agents Fail in Enterprise Environments
The core structural flaw of many early AI voice OS and text-based agent deployments is their reliance on a context-free architecture. These systems depend entirely on the foundational knowledge of the underlying Large Language Model (LLM) combined with static, hardcoded system prompts. When users ask complex, multi-turn questions requiring domain-specific enterprise data, the context-free agent either fabricates an answer (hallucination) or provides a frustratingly generic response.
Beyond poor user experience, context-free agents heavily inflate operational expenses. Because they lack precise information retrieval pipelines, developers often attempt to compensate by stuffing massive amounts of irrelevant data into the LLM's context window. This brute-force approach leads to skyrocketing token usage, unacceptable latency, and a distorted Return on Investment (ROI). To truly bridge the execution gap, enterprises must transition from context-free deployments to robust, dynamic, context-aware infrastructure.
Core Infrastructure Pillars for Enterprise AI Agents
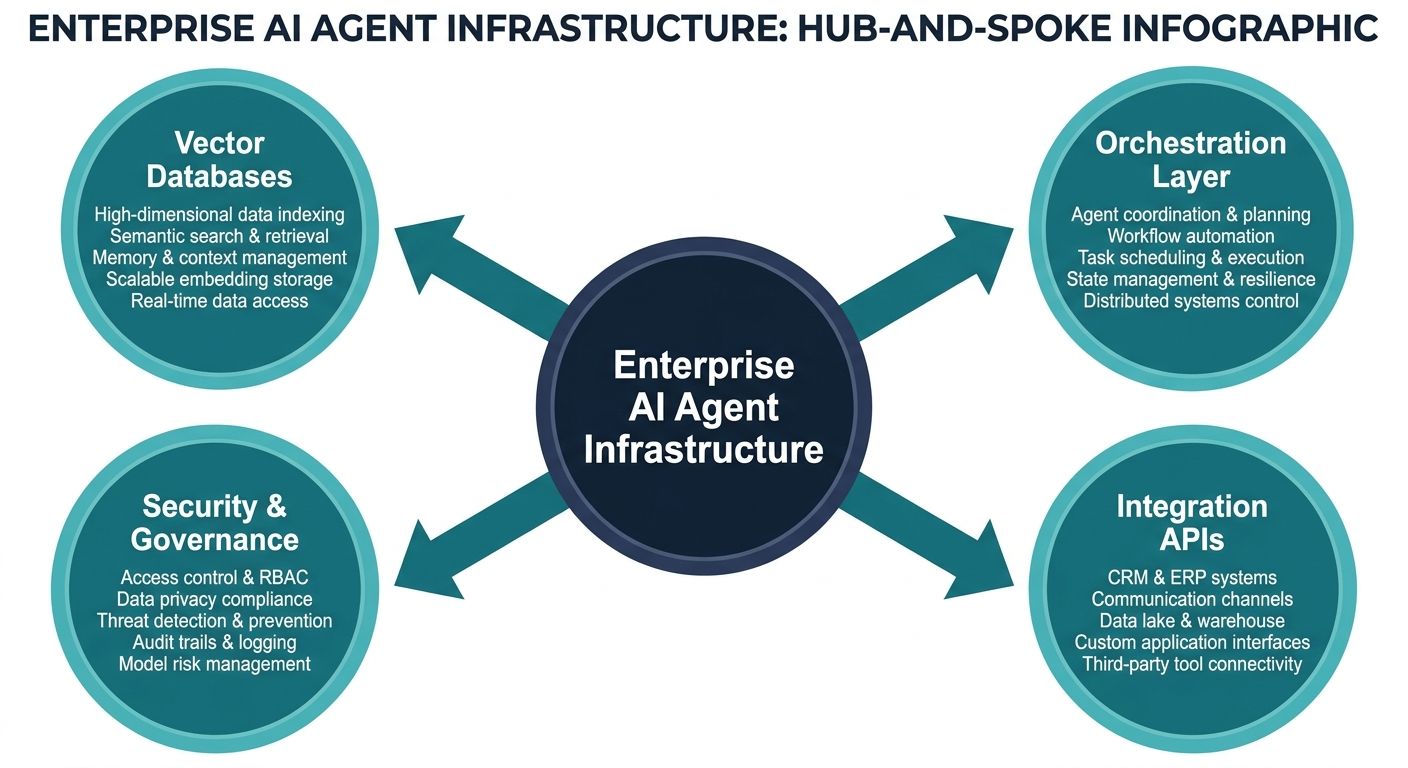
To successfully orchestrate AI agents in production, enterprises must architect a comprehensive infrastructure stack tailored for agent lifecycle management. This involves moving beyond basic scripting to implement concrete architectural patterns that support scalability, observability, and deterministic data retrieval.
1. Vector Databases and Advanced Information Retrieval Systems
Enterprise AI agents require instantaneous access to vast repositories of proprietary data. The foundation of this retrieval mechanism is the vector database. Unlike traditional relational databases, vector databases store data as high-dimensional embeddings, allowing the infrastructure to perform semantic similarity searches. By converting enterprise documents, CRM data, and historical logs into vector embeddings, the AI agent infrastructure can mathematically match user queries to the most relevant internal knowledge, effectively forming the bedrock of a robust Retrieval-Augmented Generation (RAG) pipeline.
2. Agent Orchestration and Specialized MLOps Tooling
Deploying an AI agent is not a one-time event; it is a continuous lifecycle. Standard DevOps tools are insufficient for the non-deterministic nature of AI. Enterprises must implement specialized MLOps (or AgentOps) tooling designed specifically for autonomous agents. This infrastructure must include sophisticated telemetry to monitor execution pathways, track API call success rates, log sub-agent handoffs, and measure real-time latency. Furthermore, CI/CD pipelines for AI agents must incorporate automated prompt testing and regression evaluations to ensure that an update to the agent's logic does not inadvertently degrade its reasoning capabilities.
3. Scalable Compute and Latency Optimization
For AI Voice OS applications in particular, latency is the ultimate killer of user experience. A delay of more than 500 milliseconds in a voice interaction destroys the illusion of human-like conversation. Enterprise infrastructure must utilize edge computing where appropriate, optimized inference engines, and intelligent caching mechanisms to minimize the round-trip time between speech-to-text processing, context retrieval, LLM inference, and text-to-speech generation.
Prompt Engineering vs. Context Engineering
A critical misstep in the demo-to-deployment journey is an over-reliance on prompt engineering. While crafting the perfect system prompt is valuable for defining an agent's persona and baseline constraints, it is not a scalable mechanism for knowledge delivery. Prompt engineering attempts to solve behavioral issues, but it cannot solve informational deficits.
This is where Context Engineering becomes paramount. Context engineering is the systematic, programmable process of fetching, filtering, assembling, and injecting the exact right piece of enterprise data into the agent's context window precisely when it is needed. Instead of forcing the LLM to guess the context, the infrastructure algorithmically determines the context before the LLM ever generates a token. This fundamental shift from heuristic prompting to deterministic context engineering is what makes enterprise production deployments viable.
The Five-Stage Context Arithmetic Pipeline
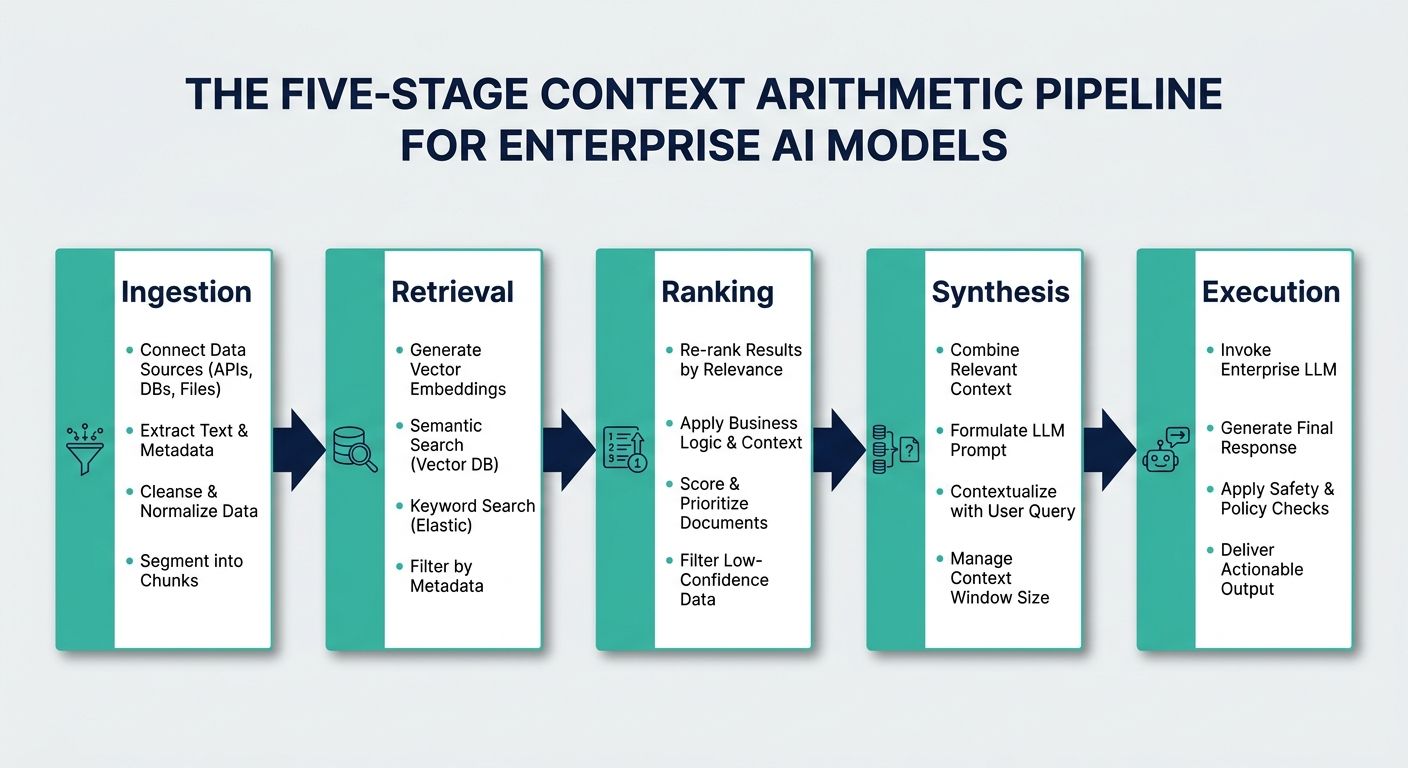
To fully realize context engineering, industry leaders are adopting rigorous computational processes. A prime architectural example of this is the Context Arithmetic framework utilized by Alchemyst's Kathan engine. Designed specifically for voice agents, Context Arithmetic is a set-algebraic pipeline that systematically determines the most relevant information to inject into an agent's brain in real-time. This pipeline consists of five distinct stages that any enterprise migration blueprint should seek to emulate.
Stage 1: Semantic Similarity Search
The process begins when a user speaks a query. The infrastructure immediately converts this query into a vector embedding and queries the enterprise vector store. Using algorithms like cosine similarity or Euclidean distance, the system retrieves a broad subset of data chunks that share semantic meaning with the user's intent. This casts a wide net to ensure no potentially relevant information is missed.
Stage 2: Metadata Filtering
Semantic similarity alone is prone to retrieving outdated or organizationally irrelevant data (e.g., retrieving a 2021 return policy instead of the 2024 policy because they are semantically identical). To solve this, the pipeline applies strict metadata filtering. Using set algebra, the infrastructure intersects the semantic search results with hard metadata constraints—such as user ID, geographic region, access permissions, and timestamps. This aggressively prunes the dataset down to only what is legally and chronologically applicable to the specific user.
Stage 3: Deduplication
Enterprise data is notoriously repetitive. Injecting redundant data into an LLM wastes expensive tokens and dilutes the model's attention mechanism. In the deduplication stage, the infrastructure scans the filtered dataset and programmatically removes duplicate or highly overlapping information chunks, ensuring the payload remains lean and highly concentrated.
Stage 4: Ranking and Re-ranking
Not all relevant information is equally important. The infrastructure must now rank the remaining, deduplicated chunks. Using advanced re-ranking models (often smaller, specialized machine learning models), the system scores each chunk based on its direct utility to answering the immediate query. The data is sorted so that the most critical information is prioritized at the top of the context window, where LLMs historically pay the most attention.
Stage 5: Contextual Injection
In the final millisecond before inference, the perfectly curated, mathematically proven context payload is injected into the LLM's prompt window alongside the user's query. Because the context is hyper-relevant, lean, and strictly filtered, the LLM is tightly constrained. It has no room to hallucinate, and the generation latency is drastically reduced due to the minimized token count.
The Definitive Migration Blueprint: From POC to Production
Understanding the theoretical infrastructure is only half the battle. Enterprises need a concrete, step-by-step migration blueprint to implement these AI and voice OS systems successfully.
Phase 1: Data Migration and Cleansing
AI is only as good as the data it accesses. Before deploying an agent, enterprises must audit their data silos. This phase involves extracting unstructured data from CRMs, internal wikis, and support tickets, cleansing it of obsolete information, and chunking it appropriately. The data is then embedded and migrated into a highly available, enterprise-grade vector database. Garbage in equals garbage out; rigorous data hygiene at this stage prevents hallucination at runtime.
Phase 2: Technical Integration and API Design
The AI agent cannot exist in a vacuum; it must read from and write to existing enterprise systems. This phase focuses on developing secure, idempotent APIs that the AI agent can call autonomously. Whether it is updating a Salesforce record or triggering a Zendesk refund, the infrastructure must support strictly defined tool-calling capabilities. Robust error handling must be built into these integrations so the agent can gracefully recover if a third-party API fails.
Phase 3: Security, Compliance, and Guardrails
Security is non-negotiable in production. The infrastructure must include input/output guardrails—specialized, low-latency models that intercept the user's prompt and the agent's response to check for prompt injection attacks, personally identifiable information (PII) leaks, and toxic content. Role-Based Access Control (RBAC) must be enforced at the vector database level to ensure agents do not retrieve data the end-user is not authorized to know.
Calculating ROI: Moving Beyond Generic Cost Savings
One of the major gaps in current enterprise AI deployments is the inability to accurately calculate Return on Investment (ROI). Traditional voice AI vendors often rely on opaque pricing models, charging per-minute, per-call, or per-seat. These models mask the inefficiencies of context-free agents, where businesses end up paying for the AI's internal processing time, latency delays, and irrelevant, meandering conversations.
To truly evaluate enterprise AI infrastructure, businesses must shift their metric to the Cost Per Qualified Outcome. This structured ROI framework focuses on the actual business value generated—whether that is a successfully resolved support ticket, a qualified sales lead, or a completed booking. By implementing highly optimized, context-aware infrastructure like the five-stage pipeline discussed above, enterprises drastically reduce token consumption, eliminate hallucination loops, and lower average handle times. This directly drives down the cost per qualified outcome, transforming the AI agent from an expensive operational experiment into a high-margin digital workforce.
Closing the Execution Gap with Next-Gen AI Infrastructure
The widening gap between dazzling AI demos and viable enterprise deployments is not a failure of the foundational models; it is a failure of infrastructure. Relying on basic API calls and heavy prompt engineering will inevitably lead to stalled deployments and negative ROI. By embracing advanced context engineering, deploying rigorous MLOps tooling, and structuring data through deterministic pipelines like Context Arithmetic, enterprises can bridge the gap.
It is time to move beyond the sandbox. By implementing a comprehensive migration blueprint—prioritizing data architecture, secure technical integration, and a ruthless focus on cost per qualified outcome—organizations can finally unlock the true, scalable potential of enterprise AI agents.




