
The Evolution of Context Engineering in Enterprise Voice AI
Enterprise voice AI has undergone a massive transformation. Simple, command-based voice bots are obsolete, replaced by dynamic, multi-turn conversational agents that must sound human, reason logically, and remember user preferences across multiple sessions. However, the shift from text-based chatbots to real-time voice agents introduces severe latency and contextual continuity challenges. This is where advanced context engineering becomes absolutely critical. Learning exactly how to implement context engineering for enterprise voice AI is the definitive key to unlocking scalable, highly personalized Voice OS platforms.
In this comprehensive guide, we provide an enterprise blueprint for building a persistent memory architecture. We will address everything from deep Retrieval-Augmented Generation (RAG) integration and Customer Relationship Management (CRM) synchronization to latency reduction, data governance, and architectural scaling. Whether you are building an AI-Native Context Management platform like Alchemyst AI or upgrading a legacy interactive voice response system, mastering the AI context layer is your foundational step toward creating voice agents that truly understand, remember, and execute complex business workflows.
What is Context Engineering, and Why Does Voice AI Demand It?
To understand how to implement context engineering for enterprise voice AI, we must first contrast it with traditional prompt engineering. Traditional prompt engineering relies heavily on injecting static instructions and limited data into a stateless context window. While this approach functions adequately for simple text-based Large Language Models (LLMs), it fails catastrophically in enterprise voice environments.
Voice conversations are inherently unstructured and messy. Human callers interrupt, change subjects mid-sentence, and frequently reference past interactions using ambiguous pronouns. If an enterprise AI agent lacks a robust, persistent context layer, it suffers from conversational amnesia. This leads to repetitive questioning, unacceptable latency spikes as the model attempts to reason from scratch, and ultimately, deeply frustrated customers.
Context engineering goes far beyond writing better prompts. It is the systemic, architectural management of information over time. It involves constructing a dedicated drop-in memory infrastructure that persists across individual sessions and different agents. For an enterprise voice AI to function effectively, it requires a state-of-the-art AI context layer—similar to the Kathan engine architecture—that intelligently retrieves, compresses, and injects highly relevant CRM and historical data into the active processing stream. Crucially, this must happen within milliseconds to prevent breaching the rigid latency budgets required for natural spoken conversation.
Core Architectural Components of an AI Context Layer
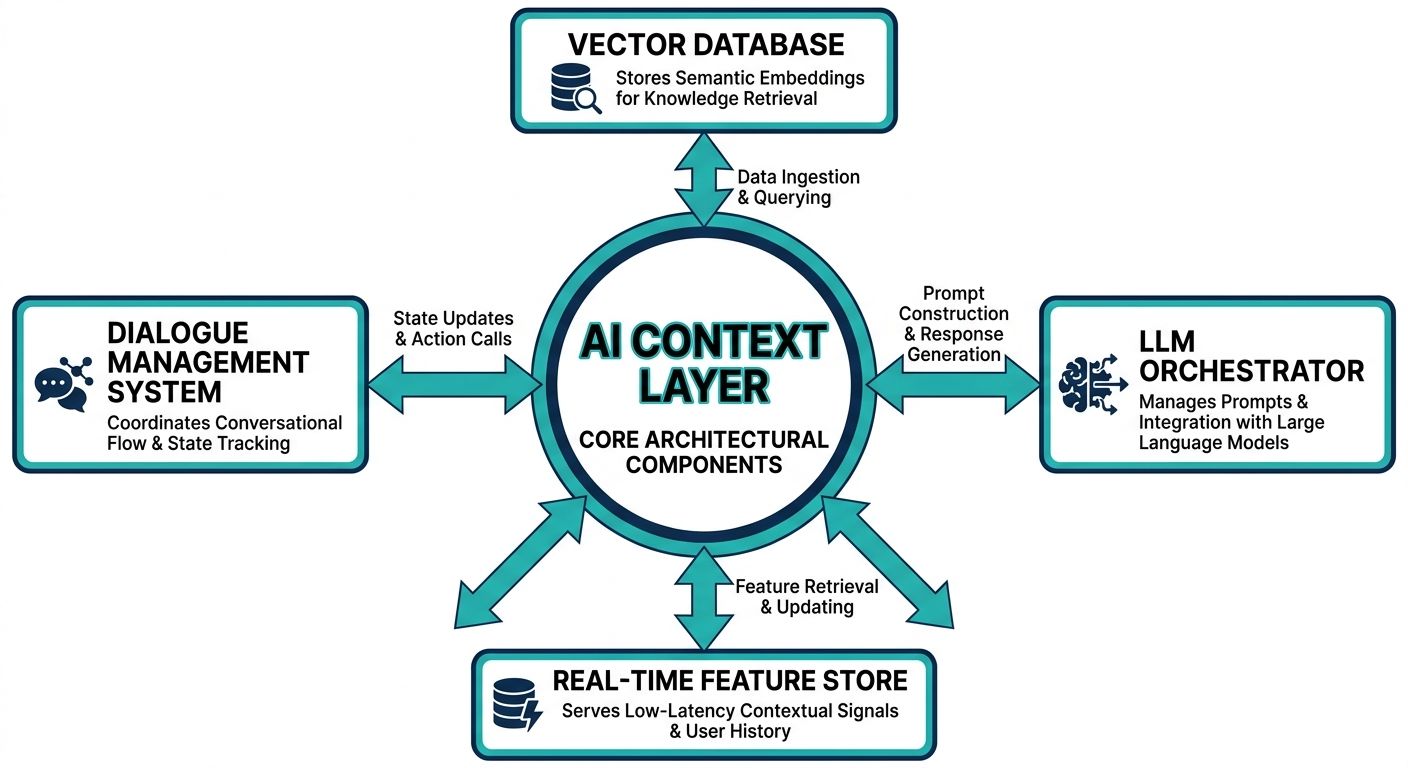
Before writing a single line of code, you must design a multi-tiered architecture that explicitly separates short-term conversational flow from long-term persistent storage. A successful context engineering implementation for voice requires three primary pillars.
1. Short-Term Working Memory
Working memory handles the immediate context of the current, active voice call. This includes tracking the current conversational turn, managing mid-sentence interruptions, and maintaining the immediate state of the user's current goal. Because voice AI requires rapid audio-to-text transcription and instant response generation, working memory must be hosted in ultra-low-latency data stores. Redis or similar in-memory caching mechanisms are typically utilized here to ensure that the agent can retrieve the last ten seconds of conversation in less than fifty milliseconds.
2. Long-Term Persistent Storage Architecture
Long-term memory is what makes a voice agent feel intelligent across multiple interactions. This layer stores historical transcripts, user preferences, past transactional data, and behavioral analytics. When implementing context engineering for enterprise voice AI, standard relational databases are often insufficient for semantic retrieval. Instead, enterprises must deploy highly optimized vector databases capable of storing and searching high-dimensional embeddings representing past conversations. This allows the AI to perform semantic searches, pulling up past context based on the meaning of the user's current query rather than relying on exact keyword matches.
3. Real-Time Context Connectors
Context connectors act as the nervous system between your AI agents and your external business data. These are dedicated APIs and middleware components that pull dynamic pricing, inventory levels, or personalized account details from CRMs, ERPs, and backend databases. By utilizing custom connectors, the voice AI can cross-reference the caller's spoken request against real-time business reality, ensuring that generated responses are not only contextually aware of the conversation but also factually accurate according to enterprise data.
Enterprise Blueprint: Step-by-Step Implementation
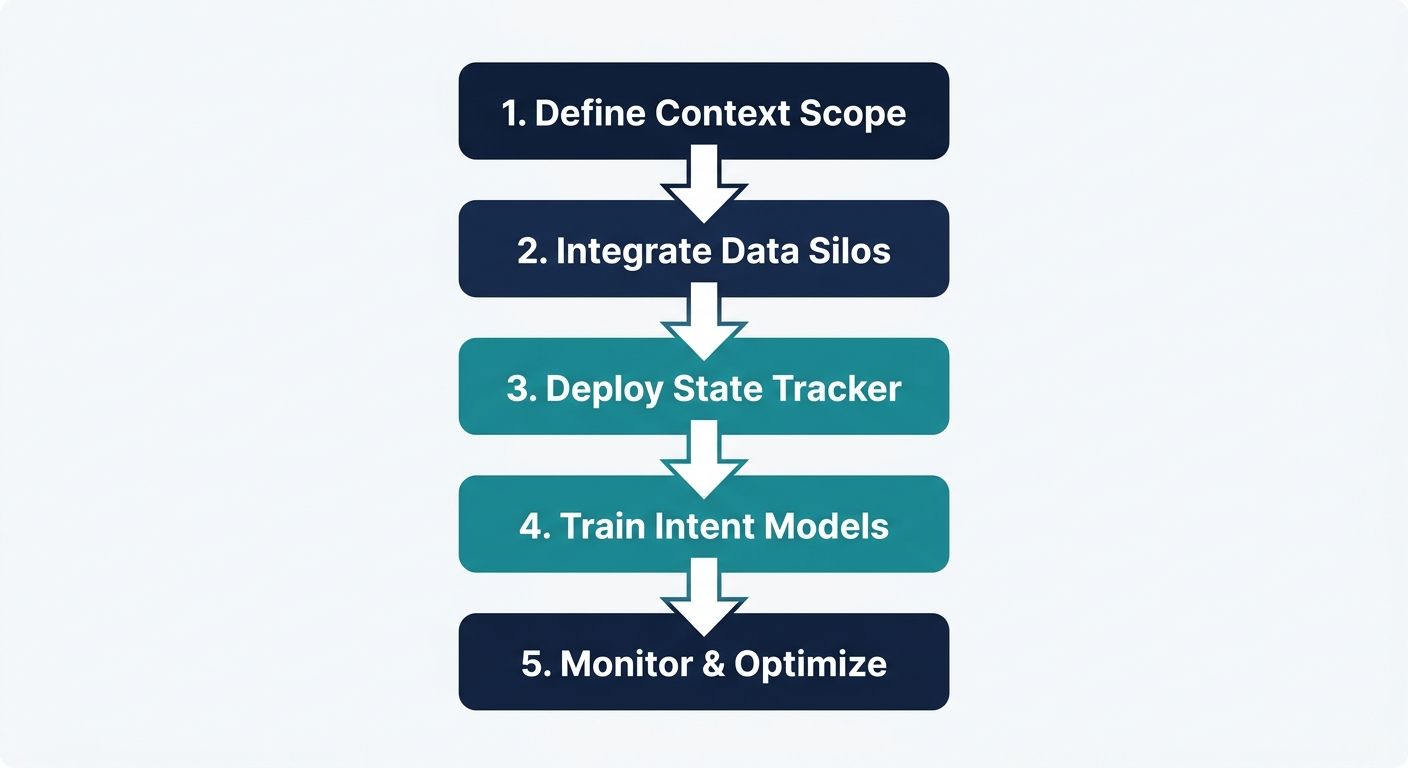
Implementing a comprehensive context management platform requires a phased approach. Follow this definitive blueprint to engineer context effectively for your enterprise voice AI applications.
Phase 1: Designing the Vector-Based Memory Architecture
The first step in implementation is establishing your long-term memory foundation. Begin by integrating a scalable vector database to store conversational embeddings. Every time a voice interaction concludes, the transcription must be processed, summarized, and converted into mathematical vectors. This is where advanced AI summarization capabilities become vital. Instead of storing massive, raw transcripts that will inevitably overwhelm an LLM's context window, you must deploy an AI model to extract key intents, decisions, and action items. These refined summaries are then vectorized and stored. When a user calls back weeks later, the system performs a similarity search against the vector database, instantly retrieving the summarized context of their previous interactions.
Phase 2: Integrating Dynamic RAG and CRM Data
Retrieval-Augmented Generation (RAG) is the engine that drives factual accuracy in enterprise AI. To implement context engineering effectively, you must fuse RAG with real-time CRM lookups. When a call connects, the system should use the caller ID or authentication token to pre-fetch relevant CRM records before the user even speaks. As the conversation progresses, semantic routers must analyze the transcription stream. If the user asks about a specific product, the semantic router dynamically queries the enterprise knowledge base (via RAG) and the inventory database (via CRM connector), injecting this exact data directly into the active prompt payload. This dual-pronged retrieval strategy ensures highly personalized, hyper-accurate voice responses.
Phase 3: Building the Memory Compression Engine
One of the largest hidden costs and performance bottlenecks in conversational AI is context window overflow. As a voice conversation extends over several minutes, the raw token count grows exponentially. Sending massive prompt payloads to the LLM increases latency—a death sentence for voice bots. To solve this, you must engineer a robust Memory Compression Engine. This system actively monitors the token count of the active session. Once a predefined threshold is reached, a lightweight, secondary LLM is triggered asynchronously to summarize the older portions of the conversation. The raw text is seamlessly replaced by a dense, highly informative summary within the working memory array. This critical context engineering technique maintains absolute conversational continuity while drastically reducing token volume, lowering API costs, and minimizing inference latency.
Phase 4: Low-Latency Optimization for Real-Time Voice
Voice is entirely different from text when it comes to latency expectations. A user chatting via text will wait five seconds for a response; a caller on the phone will assume the call dropped after two seconds of silence. Implementing context engineering for voice AI means budgeting every millisecond of the context retrieval process. Optimize your data retrieval by running vector searches in parallel with the audio transcription process. Utilize predictive context fetching—where the AI anticipates the data it might need based on the first few words of a user's sentence and begins querying databases before the user even finishes speaking. Furthermore, edge-based caching of frequently accessed contextual data can shave hundreds of milliseconds off your overall response time.
Advanced Scalability Patterns and Performance Benchmarks
Many general resources on AI memory fail to address the brutal reality of enterprise scale. What works for a local developer prototype will crash when subjected to thousands of concurrent enterprise voice calls. To scale your context engineering implementation, you must move beyond basic database queries and adopt distributed architectural patterns.
Implement a multi-layered caching strategy using semantic caching. If a user asks a common question, the system should recognize the semantic intent and serve a cached response instantly, entirely bypassing the costly vector database and LLM generation step. Furthermore, establish strict performance benchmarks. Enterprise voice AI context retrieval must consistently perform under 100 milliseconds. Monitor your Time-to-First-Byte (TTFB) meticulously. If vector search operations or CRM API calls begin dragging your TTFB above 500 milliseconds, you must aggressively optimize your indices or shift to more localized, dedicated context clusters.
Cost analysis is also vital. Vector operations and continuous prompt generation at scale are expensive. By leveraging dynamic context compression and semantic routing, enterprises can drastically reduce their computational overhead, transforming voice AI from a cost center into a scalable engine for business efficiency.
Security, Privacy, and Enterprise Data Governance
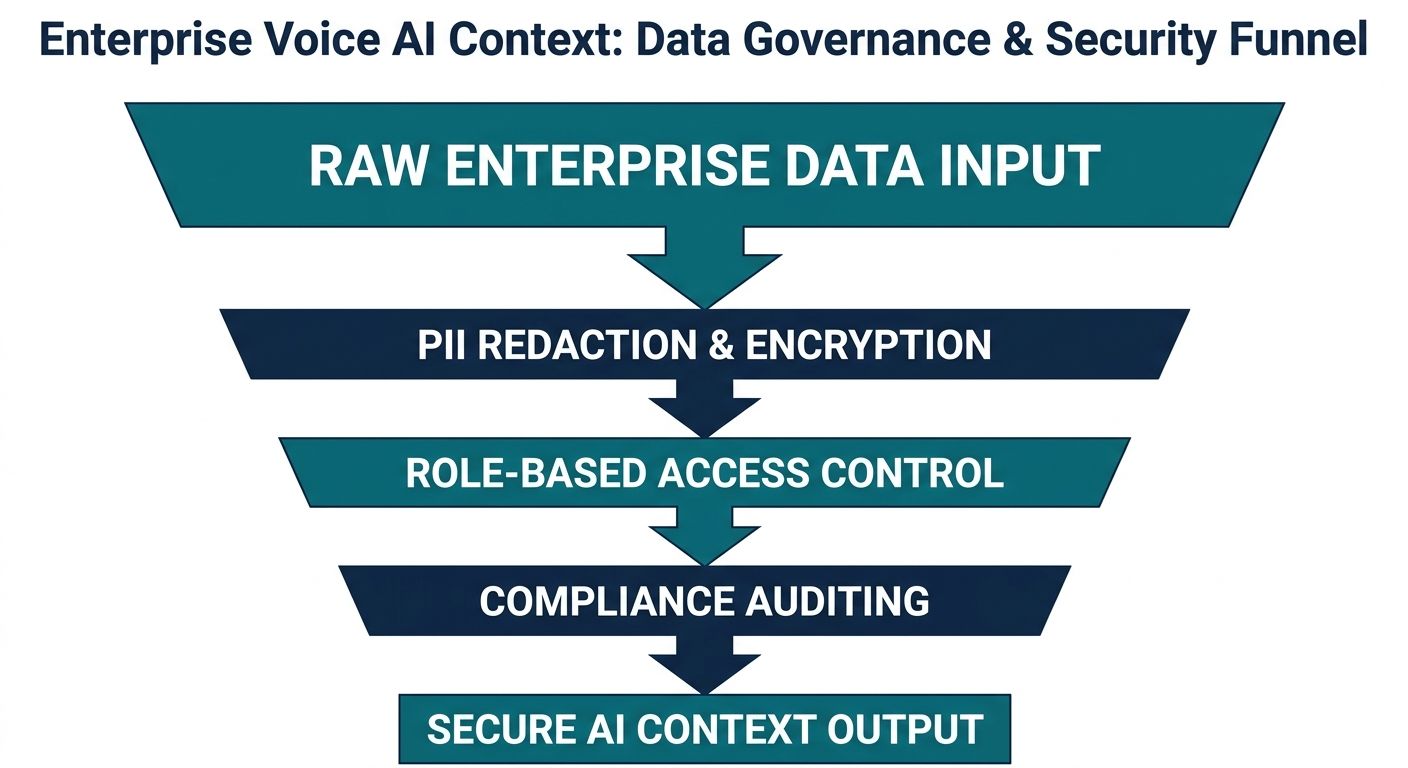
Context engineering involves the persistent storage of highly sensitive conversational data. When dealing with enterprise voice AI—especially in regulated sectors like healthcare, finance, or large-scale e-commerce—security cannot be an afterthought. A robust implementation requires integrated, real-time Personally Identifiable Information (PII) redaction.
Before any spoken transcript is passed into the long-term memory vector database or sent to an external LLM provider, it must pass through a strict sanitization layer. Credit card numbers, social security details, and protected health information must be masked or tokenized immediately. Furthermore, your context management platform must support granular, role-based access controls and comprehensive audit logging. Building an infrastructure that supports SOC2 and HIPAA compliance is non-negotiable for enterprise deployments. Context data must be siloed securely per tenant, ensuring that insights learned from one enterprise client never leak into the conversational models of another.
Robust Error Handling in Real-World Deployments
In real-world enterprise deployments, APIs fail, network latency spikes, and vector databases occasionally timeout. A critical part of how to implement context engineering for enterprise voice AI is designing resilient fallback mechanisms. What happens when the context retrieval layer fails during a live customer call?
Your voice agent must be engineered for graceful degradation. If the long-term memory retrieval times out, the agent must seamlessly fall back on its immediate working memory and politely ask clarifying questions rather than crashing or providing hallucinated information. Implement strict timeout thresholds on all context connectors. If the CRM takes longer than 800 milliseconds to return customer data, the voice OS should proceed with generic assistance protocols while triggering a background retry, ensuring the customer never experiences dead air.
Migration Blueprint: Upgrading to an AI-Native Context Platform
Transitioning from a legacy conversational bot to a context-aware Voice OS requires a strategic migration. Begin by running your new AI context layer in shadow mode alongside your existing system, passively ingesting transcripts and building the vector databases without interacting with live customers. This allows you to fine-tune the memory compression and retrieval algorithms using real-world data safely.
Ultimately, to master context engineering for conversational AI, organizations must shift their mindset. You are no longer simply prompting an LLM; you are building a comprehensive, AI-Native Context Management platform. By rigorously separating short-term and long-term memory, integrating hyper-fast RAG pipelines, deploying dynamic token compression, and enforcing strict enterprise security standards, businesses can deploy voice agents that truly rival human interaction. Embrace these context engineering principles, and your enterprise will be equipped to handle the most complex, multi-turn conversational workflows at massive global scale.




