
Introduction to the AI Context Engine API for Real-Time Voice Agents
In the rapidly evolving landscape of artificial intelligence, building a conversational agent that genuinely understands and reacts in real-time requires much more than a standard text-to-speech integration. The definitive key to unlocking natural, human-like voice interactions is a robust AI context engine API for real-time voice agents. As developers and AI engineers push the boundaries of what voice agents can achieve, the demand for sophisticated state management, ultra-low latency context retrieval, and persistent conversational memory has skyrocketed. This comprehensive guide serves as the definitive developer's reference for structuring, building, and documenting a real-world AI context engine API.
Current top-ranking pages and generic API documentations often provide high-level conceptual guides or basic voice agent blueprints. However, they consistently lack the specific, hands-on documentation required to build a dedicated context engine. Platforms that focus merely on providing a configurable API for basic voice transport often miss the critical layer of deep semantic memory. This article bridges that content gap by providing concrete examples of API endpoints, detailed request and response schemas, integration patterns, and best practices tailored specifically for real-time voice applications. By leveraging an AI-native context management solution, developers can seamlessly integrate robust context and memory capabilities into their AI-driven applications.
The Critical Need for Context Engineering in Voice AI
Voice interactions are inherently different from text-based chats. In a text interface, users can see the history of their conversation and often tolerate slight delays or minor contextual hallucinations. In real-time voice applications, however, latency and context loss are immediate dealbreakers. An AI context engine API for real-time voice agents solves the fundamental challenge of maintaining state across unpredictable spoken dialogues. Without a dedicated context engine, a voice agent is merely a stateless transcriber, incapable of recalling a user's preference stated three minutes ago or referencing a complex document in real-time.
When analyzing competitor gaps in the market, it becomes clear that many tools fall short. Solutions that primarily focus on providing a configurable API for developers to build advanced voice AI agents often emphasize the technical infrastructure of the call, such as SIP trunking or WebRTC transport, but leave the developer entirely responsible for the cognitive architecture. Conversely, tools that position themselves strictly as a memory layer often provide basic drop-in memory infrastructure but lack the integrated document retrieval and AI-native processing power required for enterprise-grade applications. A true context engine must synthesize two core capabilities: Context and Memory.
Understanding Context vs. Memory in Real-Time Applications
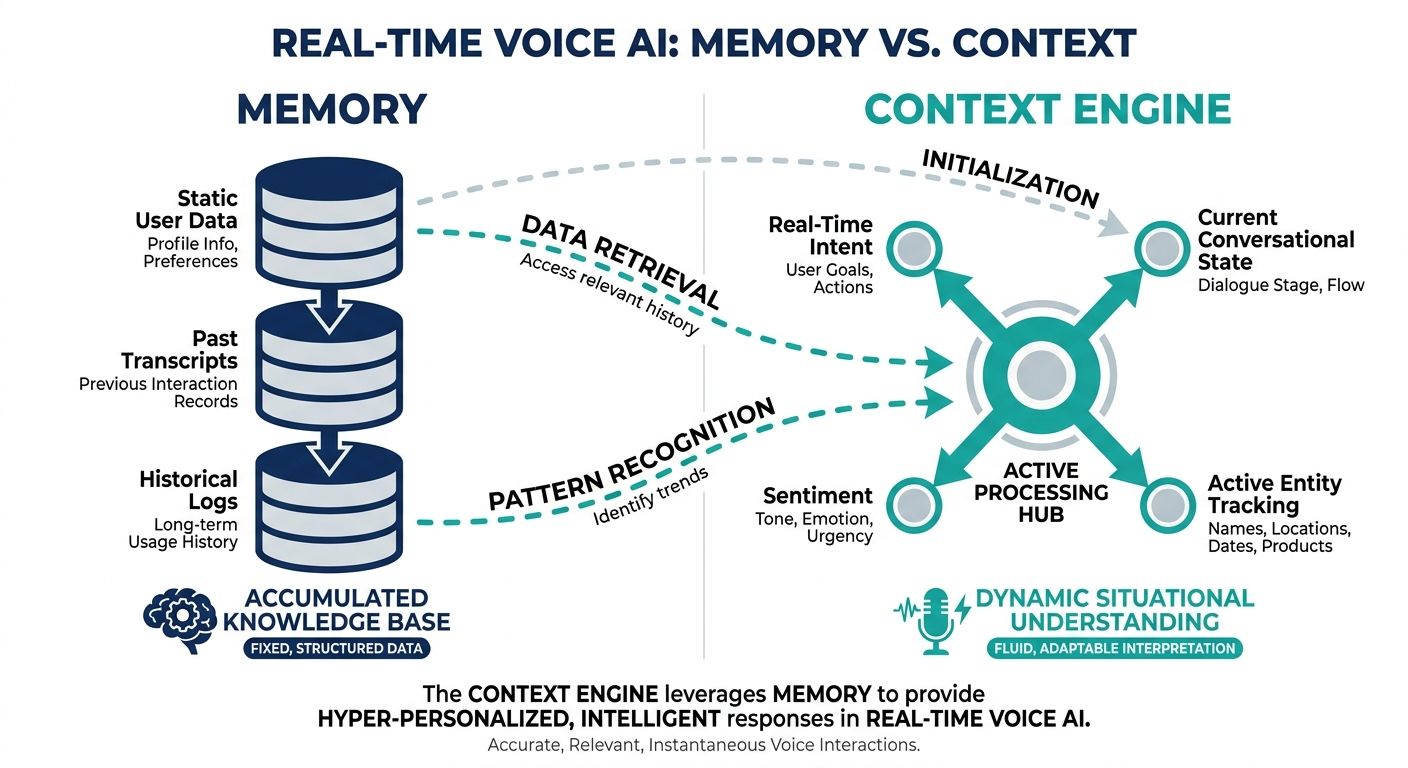
To build a high-performing real-time voice agent, developers must cleanly separate the concepts of Context and Memory. These two pillars work in tandem but serve distinct functions within the AI context engine API for real-time voice agents.
- Context: This refers to the external knowledge base. It involves storing massive repositories of documents, transcribing audio files, and retrieving highly relevant information on the fly to inform the AI's answers. In a real-time voice scenario, this is the Retrieval-Augmented Generation (RAG) pipeline optimized for millisecond response times.
- Memory: Memory is highly personal and session-specific. It tracks user preferences, historical conversation data, and nuanced interaction patterns. If a user tells a voice agent to speak slower and summarize points, the Memory layer ensures this preference persists across all future interactions without needing to be re-prompted.
Definitive Developer Reference: API Documentation and Blueprints
To truly understand how an AI context engine API for real-time voice agents operates under the hood, we must examine the specific data models and API endpoints that drive it. Below is a detailed blueprint of how a production-ready context engine is structured, featuring complete request and response schemas. This technical deep dive is designed for AI engineers and developers who require practical, actionable depth.
Authentication and Core Configuration
Every interaction with the AI context engine API requires secure authentication. Real-time voice agents often establish a persistent WebSocket connection or make high-frequency REST calls, necessitating efficient token validation. Developers authenticate using a Bearer token provided in the Authorization header. Ensure that your API keys are scoped correctly, especially when deploying voice agents in enterprise environments with strict security compliance standards.
Endpoint 1: Initializing the Voice Session Context
POST /v1/sessions/initialize
This endpoint is called the moment a user initiates a voice call. It pre-fetches the user's persistent memory and prepares the context engine for ultra-low latency RAG queries during the conversation. By eagerly loading the context, the voice agent avoids the dreaded cold-start latency that plagues many basic AI voice implementations. Proper initialization is critical for setting up the real-time pipeline.
Request Payload Schema:
- user_id (String, Required): The unique identifier for the user initiating the voice call.
- agent_id (String, Required): The ID of the specific voice agent being invoked.
- session_metadata (Object, Optional): Additional data such as device type, location, or initial conversational intent.
Response Payload Schema:
- session_id (String): The newly created session identifier used for all subsequent real-time tracking.
- active_memory (Object): A summarized profile of the user's preferences retrieved from the Memory service.
- context_ready (Boolean): Indicates whether the AI-native context engine has successfully loaded the user's RAG indices.
Endpoint 2: Real-Time Context Injection and Retrieval
POST /v1/context/retrieve
As the user speaks, their speech is transcribed into text and immediately sent to this endpoint. This is the beating heart of the AI context engine API for real-time voice agents. The endpoint queries the ingested document database and the user's interaction history simultaneously, returning a highly optimized prompt payload that your Voice LLM can instantly vocalize.
Request Payload Schema:
- session_id (String, Required): The active session identifier.
- utterance (String, Required): The real-time transcribed text of what the user just said.
- latency_budget_ms (Integer, Optional): A strict timeout limit. If the semantic search exceeds this budget, the API falls back to a simpler response to maintain the illusion of a seamless real-time conversation.
Response Payload Schema:
- retrieved_context (String): The concatenated, relevant information extracted from the RAG pipeline.
- memory_updates (Array): Any new implicit preferences detected in the user's utterance that have been queued for the Memory engine.
- suggested_agent_response (String): The fully contextualized string ready to be sent to your Text-to-Speech service.
Endpoint 3: Asynchronous Memory Consolidation
PATCH /v1/memory/update
After a voice call concludes, the system must summarize and permanently store the new conversational data. This endpoint handles the long-term state management. Advanced platforms leverage AI summarization capabilities to compress lengthy transcripts into concise, actionable memory blocks, ensuring that the database does not become bloated over time and that insights remain highly accessible.
Request Payload Schema:
- session_id (String, Required): The ID of the completed voice session.
- full_transcript (Array, Required): The complete chronological log of user and agent utterances.
- force_summarization (Boolean, Optional): Instructs the AI context engine to compress the transcript immediately rather than waiting for a batch job.
Advanced Integration Patterns for Voice AI Engineers
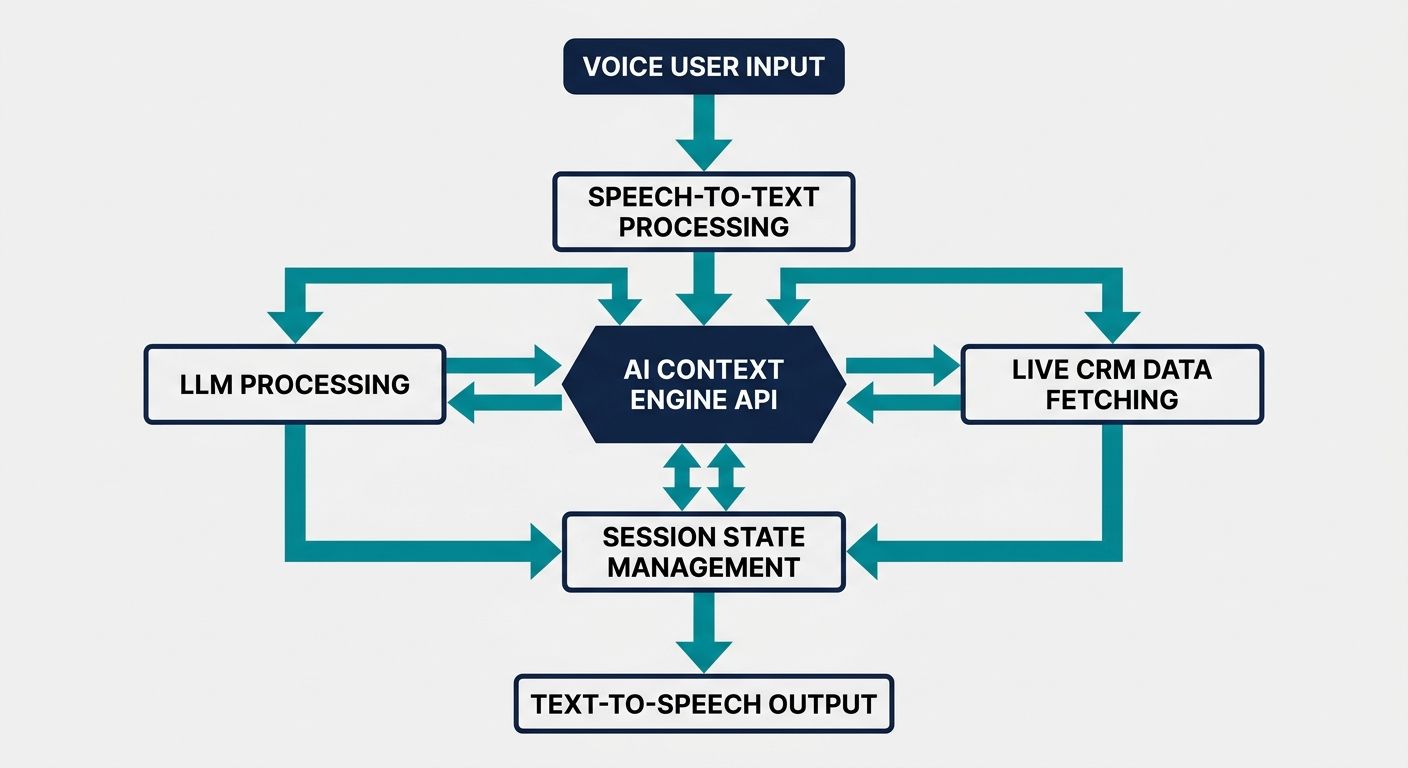
Providing an API is only half the battle; developers need to know how to weave these endpoints into complex software ecosystems. The integration capabilities of your AI context engine API for real-time voice agents dictate its true utility in production environments where scale and stability are non-negotiable.
Integrating with the Vercel AI SDK
Modern developers frequently utilize the Vercel AI SDK to build streaming AI applications. Integrating an AI context engine API into this stack requires specialized hooks. By leveraging streamlined documentation and official third-party integrations, developers can map their real-time voice streams directly into the Vercel AI SDK's state management. This integration ensures that UI components on a dashboard can update synchronously while the user is speaking to the voice agent over a WebRTC connection, providing a magical, multi-modal user experience.
Database Integrations: MongoDB and PostgreSQL
A context engine is only as powerful as the data it can access. Streamlined documentation for database integrations is critical. For instance, connecting your AI context engine API to PostgreSQL allows you to utilize pgvector for blazing-fast semantic search across structured enterprise data. Alternatively, MongoDB offers the flexibility needed to store unstructured memory objects and complex nested user preferences. When building a real-time voice agent, you must index these databases correctly so that the Context service can execute similarity searches in under fifty milliseconds.
Performance Considerations and Best Practices
When deploying an AI context engine API for real-time voice agents, performance is the ultimate metric of success. Voice conversations demand absolute fluidity. Below are the core architectural best practices developers must follow to ensure their deployments do not suffer from lag or dropped contexts.
Optimizing Payload Sizes
Real-time voice agents cannot wait for massive JSON payloads to traverse the network. When documenting context retrieval and management, developers must prioritize payload compression. Strip out all unnecessary metadata from the Context response. Instead of returning full source documents, the API should only return the highly specific exact snippet needed to answer the user's query. This strict payload management drastically reduces latency and ensures the Voice LLM begins generating audio almost instantaneously.
Managing State During Interruptions
Humans interrupt each other constantly during voice conversations. Your AI context engine API for real-time voice agents must account for this. If a user interrupts the agent, the system must instantly abort the current text-to-speech stream and send an emergency state-update to the Memory service. The API must register the interruption as an implicit signal that perhaps the user is impatient, or the context provided was incorrect. This data is fed back into the Memory service to adjust the agent's future behavior dynamically.
Security, Compliance, and Data Sovereignty
Handling voice data inherently involves processing sensitive personally identifiable information. An enterprise-grade AI context engine API must be built with strict compliance standards in mind. Features such as data anonymization, automated redaction of sensitive numbers, and regional data storage are paramount. When evaluating platforms, ensure they offer comprehensive enterprise-level support and security options that align with regulations like GDPR and HIPAA, specially when storing long-term memory logs and audio transcriptions.
Scaling Your AI Operations with the Right Platform
Building an infrastructure from scratch is an immense undertaking. Leveraging a dedicated platform like Alchemyst AI provides a scalable pathway. The platform offers diverse pricing structures tailored to different stages of voice AI development.
- Forever Free Plan: Ideal for individuals and small teams. It allows developers to test the AI context engine API for real-time voice agents, offering basic monthly transcription limits and essential context storage to validate proof-of-concepts without financial risk.
- Pro Plan: Designed for professionals and scaling startups. This tier increases storage capacity, expands language support for global voice agents, and unlocks advanced AI summarization features that are crucial for long-term memory compression and insightful analytics.
- Enterprise Plan: Engineered for larger businesses requiring highly scalable AI solutions. It includes custom AI models, extensive collaboration tools, and enterprise-level support and security options. For organizations processing millions of voice minutes, this tier guarantees dedicated infrastructure for ultra-low latency context management.
Contributing to the Context Ecosystem
The field of AI-native context management is constantly evolving. Platforms often maintain a comprehensive documentation contribution guide to foster a developer community. By utilizing frameworks like Mintlify and MDX, technical writers and developers can actively improve the documentation. This open, collaborative approach ensures that the ecosystem remains robust, providing practical and actionable instructions for structuring, validating, and submitting enhancements to the core API capabilities.
Handling Concurrent Agent Sessions
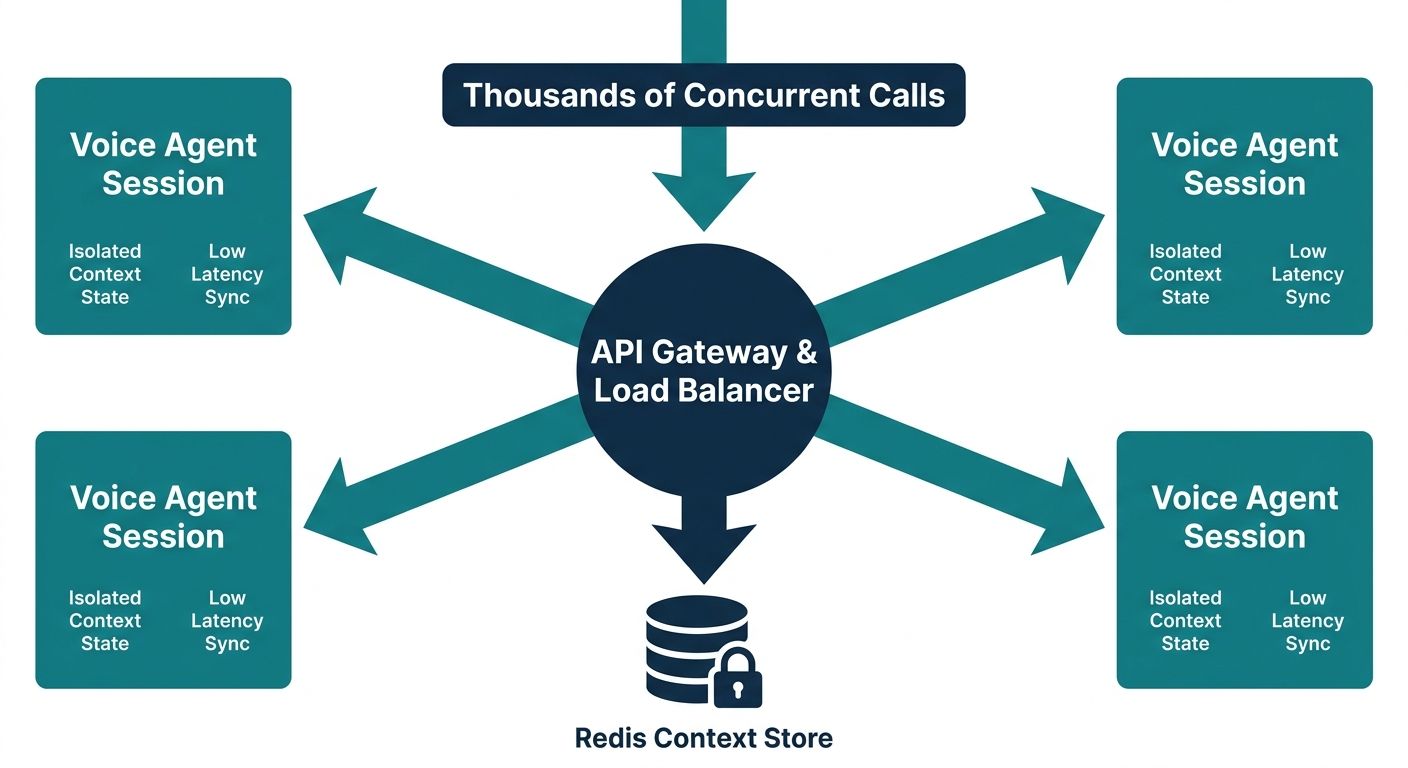
As your voice AI platform grows, you will inevitably face the challenge of managing thousands of concurrent voice sessions. The architecture behind your AI context engine API for real-time voice agents must rely on stateless edge functions and distributed caching mechanisms, such as Redis, to hold the temporary conversation state before it is committed to the long-term PostgreSQL or MongoDB database. Designing for high concurrency prevents race conditions where a user's memory might be overwritten improperly during rapid conversation turns.
Analyzing Insightful Analytics for Voice Platforms
Beyond simply driving the conversation, the data flowing through the AI context engine API is a goldmine for insightful analytics. By aggregating the memory updates and context retrieval logs, business owners and marketing professionals can identify exactly what questions customers are asking the voice agents. Customer service teams can use this AI-driven efficiency to refine their knowledge bases, ensuring the RAG pipeline is always populated with the most relevant, up-to-date documentation to resolve user queries faster.
Conclusion: The Future of Real-Time Voice Agents
The transformation of business functions through AI-driven efficiency, seamless content creation, and intelligent task automation is already underway. For business owners, marketing professionals, and customer service teams, the deployment of intelligent voice agents represents the next frontier of digital interaction. However, the success of these deployments hinges entirely on the underlying architecture.
By thoroughly understanding and implementing a dedicated AI context engine API for real-time voice agents, developers can transcend the limitations of stateless voice bots. Embracing deep integration patterns, rigorous performance optimization, and sophisticated Memory and Context services ensures that your voice agents are not just hearing users, but truly listening, remembering, and understanding. As you embark on building your next-generation voice AI stack, let this definitive developer's reference guide your architectural decisions, ensuring a robust, scalable, and highly contextual conversational experience for every single user interaction.




