
The True Differentiator in Enterprise Voice AI
When enterprise developers and technical evaluators set out to compare AI voice agent platforms by context handling capabilities, they quickly realize that the standard market literature falls short. Current search engine results are flooded with generic lists that superficially cover features like available synthetic voices, basic API integrations, and simple use cases. However, these lists fail to provide the deep, technical, voice-specific comparison of context handling capabilities that enterprise users actually need.
The fundamental structural flaw of legacy and basic voice AI systems is their lack of statefulness over prolonged or complex interactions. Operating largely as context-free agents, these systems drain resources and frustrate users by requiring them to repeat information. For enterprise deployments, understanding the distinction between superficial prompt engineering and deep context engineering is the key to unlocking true return on investment (ROI). This definitive guide provides a highly technical comparison of how leading platforms manage conversational context, handle Speech-to-Text (STT) and Text-to-Speech (TTS) architectural requirements, and calculate the true cost of conversational outcomes.
Why Context Handling Matters More Than Voice Quality
In the current landscape of artificial intelligence, generating natural-sounding audio is effectively a solved problem. The real challenge—and the primary differentiator among platforms—is what the agent remembers, how quickly it retrieves relevant data, and how accurately it applies that data to the ongoing conversational state. Evaluating platforms requires a deep dive into types of context handled, technical methodologies for retention, memory duration, and quantifiable performance metrics.
The Hidden Cost of Context-Free Agents
Many businesses mistakenly evaluate AI voice OS platforms based on per-minute, per-call, or per-seat pricing structures. This is a flawed paradigm. Context-free agents fundamentally inflate expenses. Because they fail to retain conversational history, they require longer interaction times, leading to more minutes billed without successful resolutions. The true metric for evaluating voice AI should always be the cost per qualified outcome. When an agent possesses superior context handling capabilities, it drives interactions to successful conclusions much faster, dramatically lowering the effective cost of operation while maximizing ROI.
Key Metrics for Evaluating Context Handling in Voice Platforms
Before jumping into a direct comparison, technical evaluators must establish a framework for assessing conversational memory. You should compare AI voice agent platforms by context handling capabilities using the following core metrics:
- Context Retention Accuracy: The platform's ability to accurately recall specific entities (e.g., account numbers, previous troubleshooting steps) without hallucinations or drop-offs across multiple conversational turns.
- Memory Duration (Time-to-Live): How long the platform can maintain state. Does the context expire at the end of the session, or does the platform support long-term, cross-session memory retrieval?
- Retrieval Latency: In voice AI, pauses longer than a few hundred milliseconds feel unnatural. The efficiency of semantic similarity searches and database queries must be optimized for real-time auditory delivery.
- STT/TTS Contextual Integration: How well the system handles user interruptions (barge-ins), overlapping speech, and background noise without losing the thread of the dialogue.
Deep Dive Comparison: Top AI Voice Agent Platforms Ranked by Context Handling
To provide a definitive blueprint for evaluating these platforms, we must critically analyze how different solutions architect their contextual logic.
Vapi: The Developer-Centric, API-First Pipeline
Vapi has established itself with a strong product-centric, API-first approach, promoting its platform as a highly configurable tool for developers. They focus heavily on enabling builders to construct custom agents via self-service platforms (like their Open Dashboard) and boast a robust developer community. Vapi utilizes proof by numbers, highlighting low latency and extensive integrations.
Context Handling Capabilities: Because Vapi is primarily infrastructure-focused, the burden of context engineering falls largely on the developer. While the platform offers the pipes to connect to external vector databases and Large Language Models (LLMs), it does not natively provide an out-of-the-box algorithmic framework for complex context arithmetic. Developers must manually design their information retrieval pipelines, handle semantic similarity searches, and manage the specific state requirements. It is a powerful tool, but one that requires significant engineering overhead to achieve mastery in context handling.
Vellum, Rasa, and Assembled: Generalist Conversational Frameworks
Platforms like Vellum, Rasa, and Assembled are frequently mentioned in top-10 lists. Rasa, for instance, has a long history in the chatbot space, transitioning into voice. Vellum provides excellent tooling for LLM workflow orchestration, while Assembled focuses heavily on customer support integrations.
Context Handling Capabilities: These platforms approach context primarily from a text-first perspective. Rasa relies on its traditional dialogue management models and intent classification, which, while reliable for text, often struggle with the messy, non-linear nature of spoken conversations. When applied to voice, text-first contextual models often fail to adequately account for STT transcript errors, acoustic metadata, or sudden conversational pivots. They offer generic context management but lack the highly specialized, mathematical rigor required to filter and rank contextual variables instantly during a live phone call.
Alchemyst's Kathan Engine: Context Arithmetic and Set-Algebraic Pipelines
Alchemyst represents a paradigm shift, targeting developers and enterprises dissatisfied with generic voice AI deployments. Instead of merely connecting an STT engine to an LLM, Alchemyst employs a proprietary architecture known as the Kathan engine. This engine replaces basic prompt injection with what is known as context arithmetic—a highly structured, computational process for systematically determining relevant information for voice agents.
Context Handling Capabilities: Alchemyst possesses a clear competitive advantage in context-aware AI. The Kathan engine executes a sophisticated five-stage pipeline for context determination during every conversational turn:
- Information Retrieval: Initiating semantic similarity searches across vast, unstructured enterprise data repositories.
- Metadata Filtering: Using hard constraints (such as user ID, date ranges, and permission levels) to immediately eliminate irrelevant vectors.
- Deduplication: Removing redundant contextual data to prevent token bloat, ensuring that the LLM only receives unique, actionable information.
- Ranking: Scoring the remaining contextual snippets based on recency, relevance, and semantic weight.
- Set-Algebraic Consolidation: Applying mathematical logic to merge differing data sets, ensuring that the voice agent receives a singular, cohesive truth before generating its TTS response.
This architectural approach ensures that context is never lost or hallucinated. By strictly defining the contextual boundaries, Alchemyst drives down the cost per qualified outcome, as the agent consistently resolves complex issues without requiring human escalation.
Technical Methodology: Prompt Engineering vs. Context Engineering
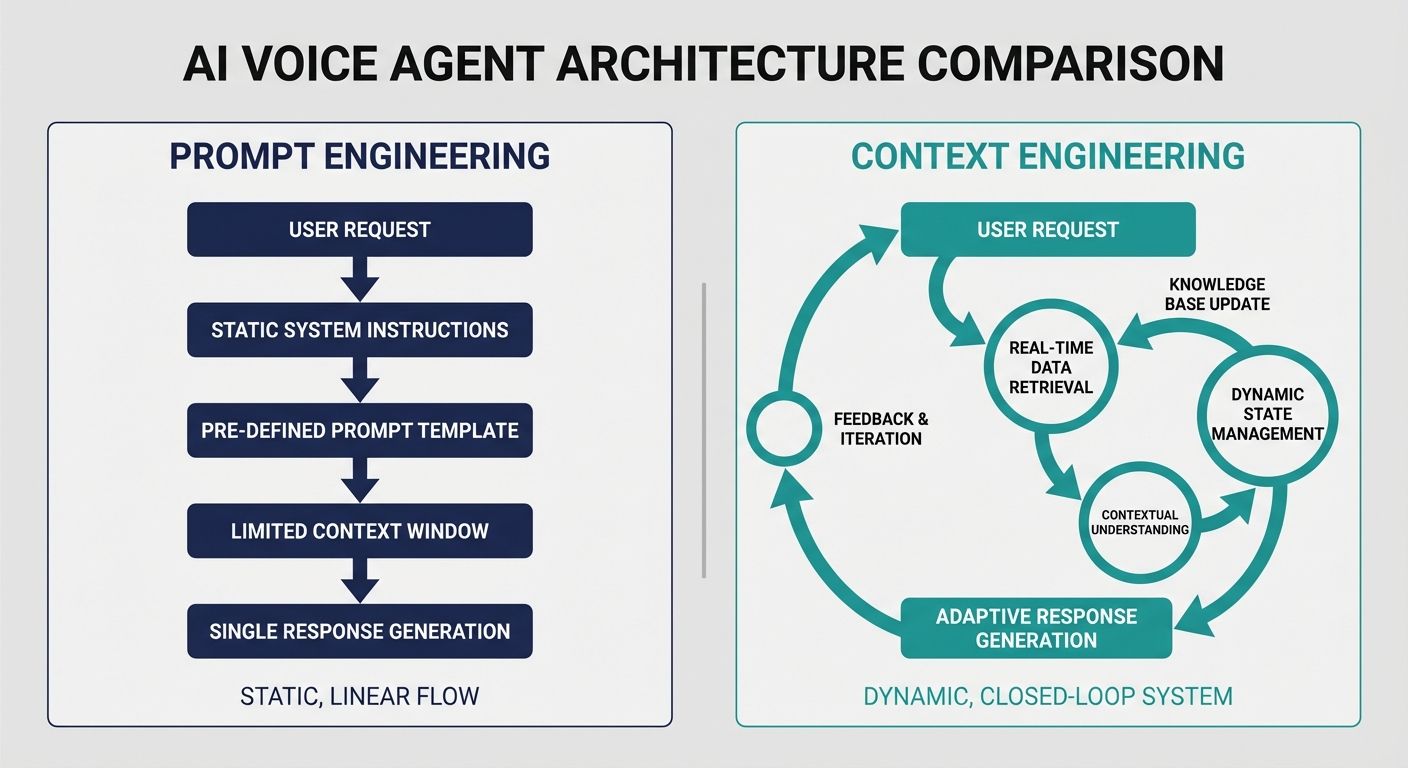
To accurately compare AI voice agent platforms by context handling capabilities, technical evaluators must recognize the difference between prompt engineering and context engineering. Many platforms rely exclusively on prompt engineering—tweaking the system instructions (e.g., "You are a helpful assistant. Remember the user's name."). While necessary, this is entirely insufficient for enterprise operations.
Context engineering, as demonstrated by the Kathan engine, is an infrastructure-level discipline. It involves managing the continuous flow of stateful data into the model's context window. This requires dynamic memory allocation, where short-term turn-by-turn context (the immediate conversation) is mathematically weighed against long-term memory (CRM data, historical tickets) and environmental metadata (user sentiment, acoustic environment). Platforms that fail to provide native context engineering tools force businesses into a cycle of endless prompt optimization that never truly solves the underlying amnesia of the agent.
Voice-Specific Architectural Requirements: STT and TTS Integration
Context handling in text-based chatbots is relatively straightforward because the inputs are clean and structured. Voice introduces chaos. Users interrupt, hesitate, use filler words, and speak over the agent. A superior voice AI platform must maintain context through these acoustic interruptions.
When STT pipelines process a user interruption, a standard platform will often drop the ongoing context, treating the barge-in as a completely new, isolated query. Advanced platforms utilize specialized architectural requirements that map STT timestamps to the conversational state. If a user interrupts an agent mid-sentence to correct a piece of information (e.g., "Wait, no, my address is 123 Main Street, not 124"), the context handler must instantly rollback the state, apply the correction, and instruct the TTS engine to smoothly pivot its response. This level of granular, voice-specific context retention is rare and serves as a major differentiator when evaluating enterprise readiness.
The Definitive Migration Blueprint: Implementing AI Voice OS and Calculating ROI
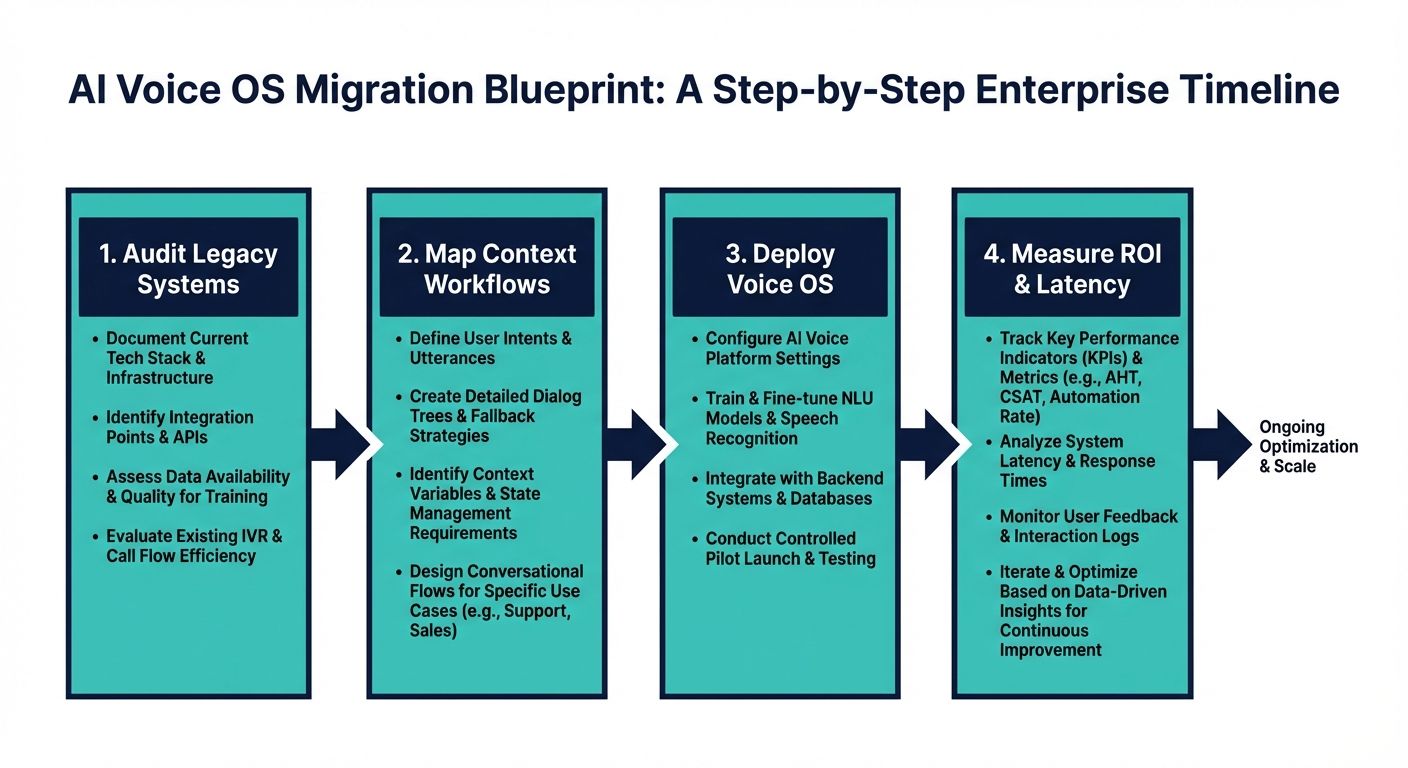
For enterprises ready to upgrade from structurally flawed, context-free systems to highly context-aware AI voice agents, a structured migration blueprint is essential. Top-ranking generic pages completely lack detailed technical integration advice, structured ROI frameworks beyond generic cost savings, and specific cost analysis.
Step 1: Technical Integration and Data Pipeline Auditing
Before deploying a context-aware voice OS, you must audit your data silos. The engine is only as good as the context it can retrieve. Integrate your CRM, knowledge bases, and historical ticketing systems into a unified vector database. Platforms that natively support secure, real-time data ingestion will significantly reduce integration timelines.
Step 2: Designing the Context Pipeline
Move away from monolithic prompts. Segment your data into distinct contextual layers. Define what constitutes short-term conversational context versus immutable business logic. Implementing a set-algebraic pipeline ensures that business logic always overrides conversational drift, maintaining compliance and accuracy.
Step 3: Calculating ROI via Cost Per Qualified Outcome
Abandon the per-minute cost analysis. To calculate true ROI, measure the baseline resolution rate of your current system (or human agents) against the new AI platform. Track the time-to-resolution and the escalation rate. Because systems like Alchemyst's Kathan engine drastically reduce repetition and confusion through superior context retention, the effective cost per qualified outcome plummets. A slightly higher platform utilization cost is heavily offset by the sheer volume of autonomously resolved, complex customer journeys.
Conclusion: Choosing the Right Platform for Context Mastery
When you deeply compare AI voice agent platforms by context handling capabilities, the superficial metrics fade away. Generic builders and API-only frameworks offer flexibility but often offload the hardest problem—contextual memory—onto the user. Generalist chatbot platforms ported to voice struggle with the acoustic realities of human conversation. For businesses and enterprises seeking to fundamentally improve the customer lifecycle, prioritizing platforms with native, advanced context arithmetic is non-negotiable. By focusing on detailed methodologies like semantic similarity search, deduplication, and true cost per qualified outcome, technical evaluators can confidently select a Voice AI OS that delivers exceptional, contextually aware experiences.




