
Understanding the AI Context Layer for Enterprise Voice Agents
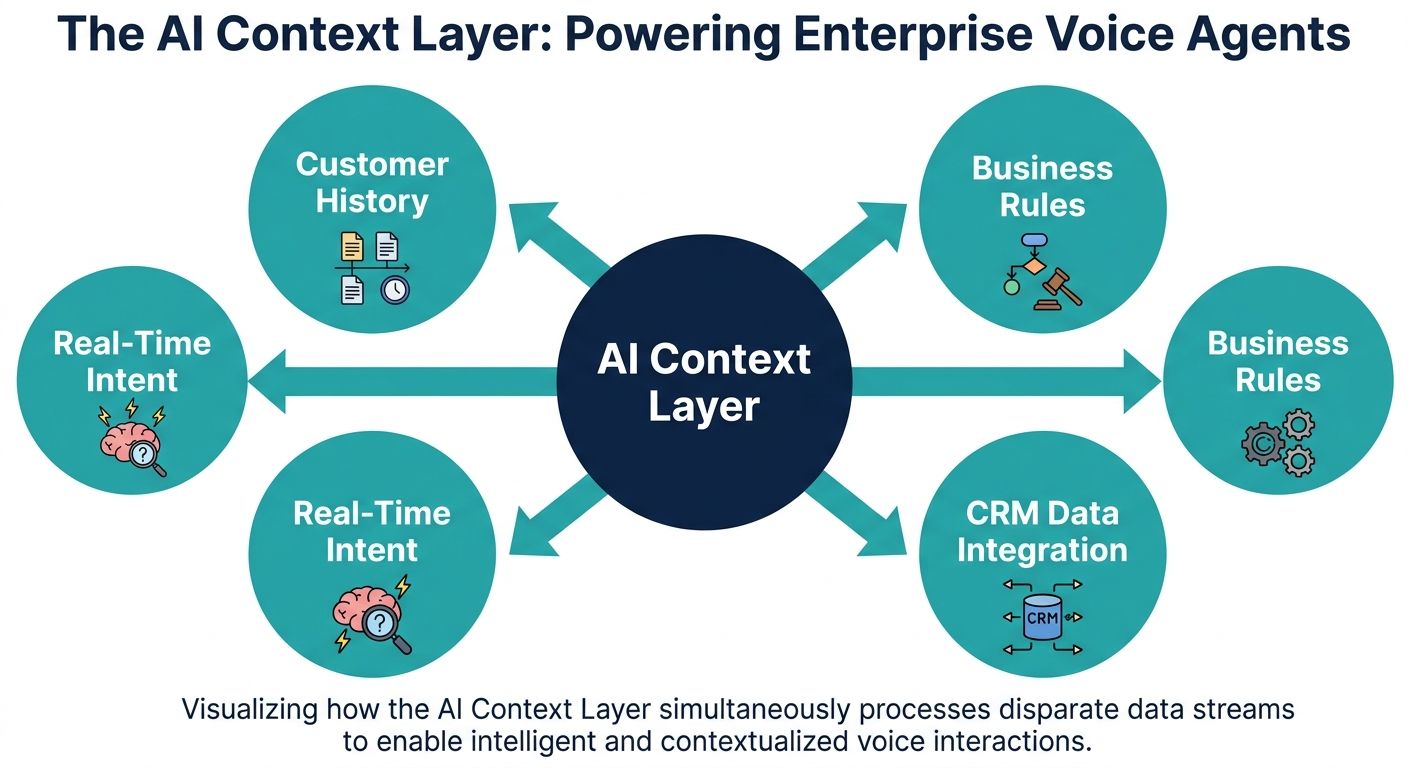
In the rapidly evolving landscape of enterprise artificial intelligence, the distinction between a rudimentary chatbot and an intelligent voice assistant lies fundamentally in how information is processed and retained. When evaluating the keyword question, what is an AI context layer for enterprise voice agents, the answer extends far beyond basic conversational memory. An AI context layer is a sophisticated, highly optimized architectural framework designed specifically to bridge the gap between unstructured enterprise data and real-time, dynamic voice interactions. Unlike generic AI text agents that process queries asynchronously, enterprise voice agents operate within strict latency budgets and must navigate the unpredictable nuances of human speech.
For enterprise developers and technical evaluators, understanding the context layer requires moving beyond standard prompt engineering. It necessitates a deep dive into context engineering, information retrieval pipelines, and computational architectures that can systematically determine relevant information in milliseconds. This comprehensive guide serves as a technical primer on the specialized requirements of voice-centric AI context layers, exploring how advanced systems like Alchemyst's Kathan engine utilize context arithmetic to power the next generation of AI Voice Operating Systems (Voice OS).
Why Voice Agents Demand a Specialized Context Layer
Most broad discussions around AI context layers focus heavily on text-based systems. However, voice agents introduce a myriad of unique architectural challenges that render text-centric context layers obsolete. The primary differentiator is the real-time processing requirement. When a user interacts with a text interface, a latency of two to three seconds is often acceptable. In voice communication, any delay exceeding 500 milliseconds breaks conversational flow, causing users to interrupt the system or assume the agent has failed. Therefore, a context layer for voice agents must process historical dialogue, query external enterprise databases, and inject context into the Large Language Model (LLM) simultaneously.
The Latency Budget: Real-Time STT and TTS Integration
An enterprise voice agent operates through a complex pipeline involving Speech-to-Text (STT) transcription, natural language understanding via an LLM, and Text-to-Speech (TTS) synthesis. The AI context layer sits at the heart of this pipeline. As the STT engine transcribes the spoken word, the context layer must preemptively retrieve relevant customer data and conversational history. This ensures that by the time the LLM generates a response, it is fully informed, allowing the TTS engine to begin streaming natural, contextually accurate audio immediately. Without a highly optimized context layer, the cumulative latency of STT, database querying, LLM generation, and TTS rendering would result in unacceptably sluggish interactions.
Overcoming Spoken Language Nuances and STT Hallucinations
Another critical requirement of a voice-specific context layer is handling the messiness of spoken language. Users rarely speak in perfectly structured sentences. They use filler words, correct themselves mid-sentence, and frequently interrupt. Furthermore, STT engines often misinterpret industry-specific jargon or phonetic similarities resulting in phonetic collisions. A robust AI context layer assists in correcting these STT hallucinations. By maintaining deep contextual awareness of the customer profile and the ongoing conversation, the system can infer the correct meaning of a garbled transcription. For instance, if a user mentions a product name that sounds similar to a common dictionary word, the context layer cross-references the enterprise catalog to accurately interpret the user's intent.
Prompt Engineering vs. Context Engineering in Voice OS
A common misconception in the developer community is conflating prompt engineering with context engineering. While prompt engineering focuses on optimizing the instructions given to an LLM, context engineering is the complex data infrastructure that determines what information gets fed into those prompts dynamically. Basic API-first platforms often leave the burden of context engineering entirely to the developer, providing a blank canvas but lacking the underlying infrastructure to scale enterprise-grade memory.
Context engineering involves the systematic retrieval, filtering, and structuring of data from multiple enterprise silos (CRMs, ERPs, knowledge bases) before the LLM even sees it. For voice agents, this process must be mathematically precise to avoid exceeding the LLM's token limits and to minimize processing time. This is where advanced methodologies like context arithmetic come into play, replacing brute-force data injection with highly selective, algorithmic data retrieval.
The Architecture of Context: Deep Dive into Context Arithmetic
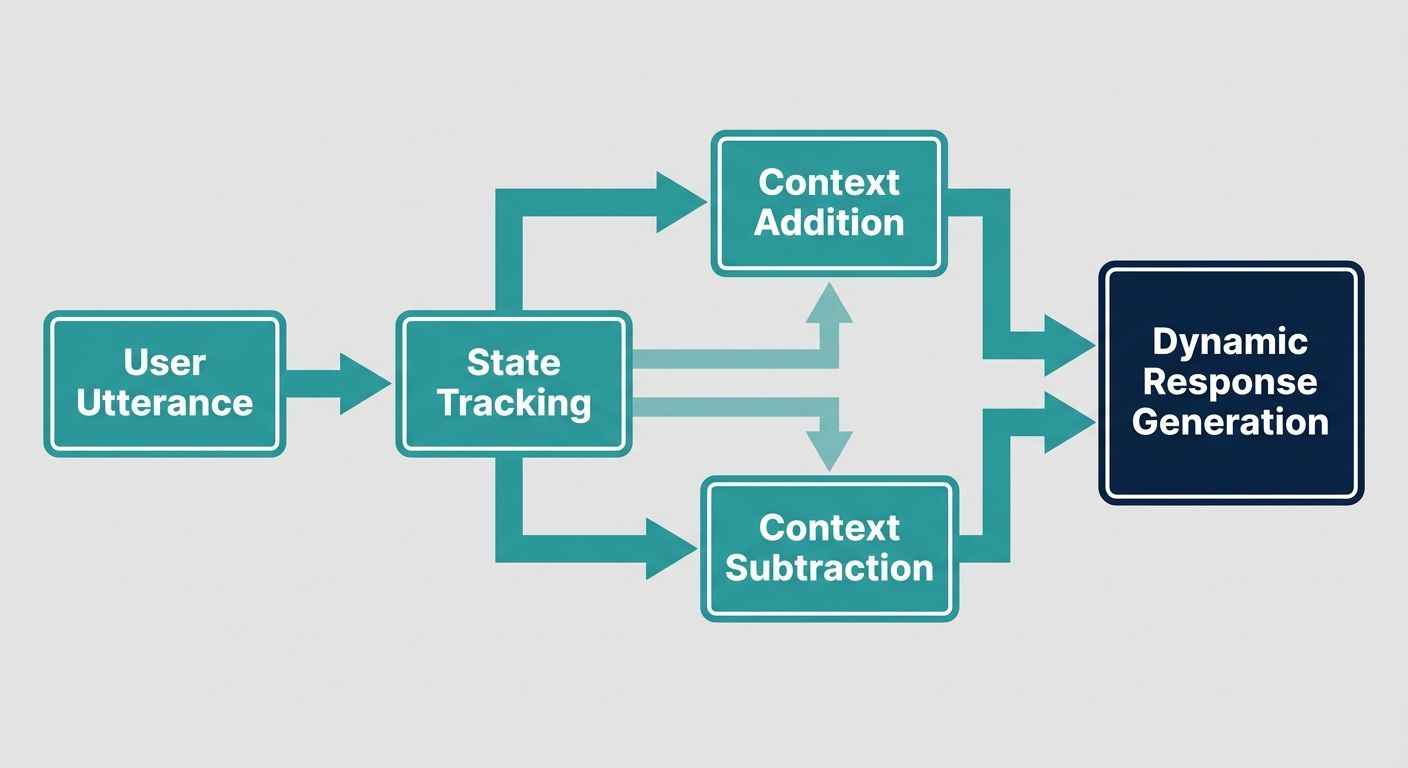
To truly understand what makes an AI context layer effective for enterprise voice agents, one must examine the computational processes powering it. Alchemyst's Kathan engine provides an industry-leading blueprint for this through its proprietary context arithmetic methodology. This approach treats contextual data retrieval as a highly optimized set-algebraic pipeline, ensuring the voice agent only receives the exact, deduplicated information necessary to formulate a response.
The context arithmetic pipeline operates through a stringent five-stage computational process designed specifically to support real-time voice interactions.
Phase 1: Semantic Similarity Search and Vectorization
The first stage involves advanced information retrieval. As a user speaks, their query is converted into a high-dimensional vector. The context layer then performs a semantic similarity search across the enterprise's vectorized knowledge base. Unlike simple keyword matching, semantic search understands the underlying intent of the user's query. This ensures that even if the user phrases a question vaguely, the context layer retrieves the conceptually correct documentation or customer history.
Phase 2: Metadata Filtering and Access Control
Retrieving information purely based on semantic similarity is insufficient for enterprise environments governed by strict security and compliance rules. The second stage applies rigorous metadata filtering. This step ensures that the voice agent only retrieves information that the specific user is authorized to access. By implementing role-based access controls at the context layer level, enterprises can safely deploy voice agents that handle sensitive customer data without risk of data leakage or cross-tenant contamination.
Phase 3: Deduplication of Conversational Memory
One of the most significant challenges in long-form voice interactions is token bloat. If a context layer continually feeds the entire conversational transcript and retrieved documents into the LLM, latency will spike, and compute costs will skyrocket. The deduplication stage uses computational algorithms to identify and remove redundant information. It distills the context down to its most essential elements, ensuring the prompt remains lean and the response time remains under the critical voice latency threshold.
Phase 4: Dynamic Context Ranking
After filtering and deduplicating the retrieved data, the context layer must prioritize what is most immediately relevant to the current turn in the conversation. The ranking stage often utilizes cross-encoder models to evaluate the relationship between the user's immediate query and the retrieved context chunks. The most critical pieces of information are scored highest and placed closest to the final LLM instruction, ensuring the model heavily weighs this data when generating its spoken response.
Phase 5: The Set-Algebraic Pipeline Injection
The final phase is the defining feature of context arithmetic. Instead of simply concatenating the ranked data, the system applies set-algebraic operations. It calculates intersections (where multiple data points corroborate an answer) and unions (combining distinct but necessary pieces of information) to formulate a mathematically precise context payload. This payload is then injected into the LLM. This architectural sophistication is what separates enterprise-ready voice agents from hobbyist API wrappers that struggle to maintain conversational coherence over time.
Evaluating Voice Agent Platforms on Context Handling Mastery
When technical evaluators and enterprise architects assess AI Voice OS platforms, they often encounter a stark divide. On one side are product-centric, API-first platforms that prioritize developer self-service and quick deployments. These platforms often promote proof by numbers, highlighting metrics like total concurrent calls or integration counts. However, they frequently lack a comprehensive, built-in context layer, forcing development teams to build complex Retrieval-Augmented Generation (RAG) pipelines from scratch to support basic conversational memory.
On the other side are enterprise-grade solutions like Alchemyst's Kathan engine, which are fundamentally built around context-aware AI. To evaluate these platforms effectively, enterprises must look beyond generic cost savings and examine context handling mastery. This involves assessing the depth of conversational memory, the duration over which context persists (session-based vs. lifecycle-based), the platform's ability to seamlessly integrate API payloads from external systems in real-time, and its proven metrics in reducing STT latency through preemptive context loading. Platforms that natively handle these voice-specific architectural requirements offer a significantly higher return on investment and a vastly superior end-user experience.
Overcoming the Hidden Costs of Context-Free Voice Agents
The financial implications of implementing an inferior context layer are profound. Many businesses initially adopt voice AI solutions based on attractive per-minute, per-call, or per-seat pricing structures. However, these models obscure the hidden costs associated with context-free agents. A voice agent lacking deep contextual awareness will invariably loop through generic questions, force users to repeat themselves, and struggle to complete complex multi-step workflows. This results in longer call durations, frustrating user experiences, and ultimately, a failure to deflect tickets from human agents.
Shifting to Cost Per Qualified Outcome
To accurately measure the ROI of an enterprise voice agent, organizations must transition their analytical frameworks from simple per-minute costs to the Cost Per Qualified Outcome. This metric evaluates the true financial efficiency of the system by measuring how much it costs to successfully resolve a customer issue without human intervention. Context-aware AI drastically lowers the Cost Per Qualified Outcome. Because the AI context layer instantly surfaces the right CRM data, understands the user's history, and navigates the conversation intelligently, interactions are shorter, more accurate, and highly effective. The proprietary context arithmetic engine ensures that computational resources are not wasted processing irrelevant data, directly translating into scalable enterprise ROI.
The Definitive Migration Blueprint for Context-Aware Voice OS
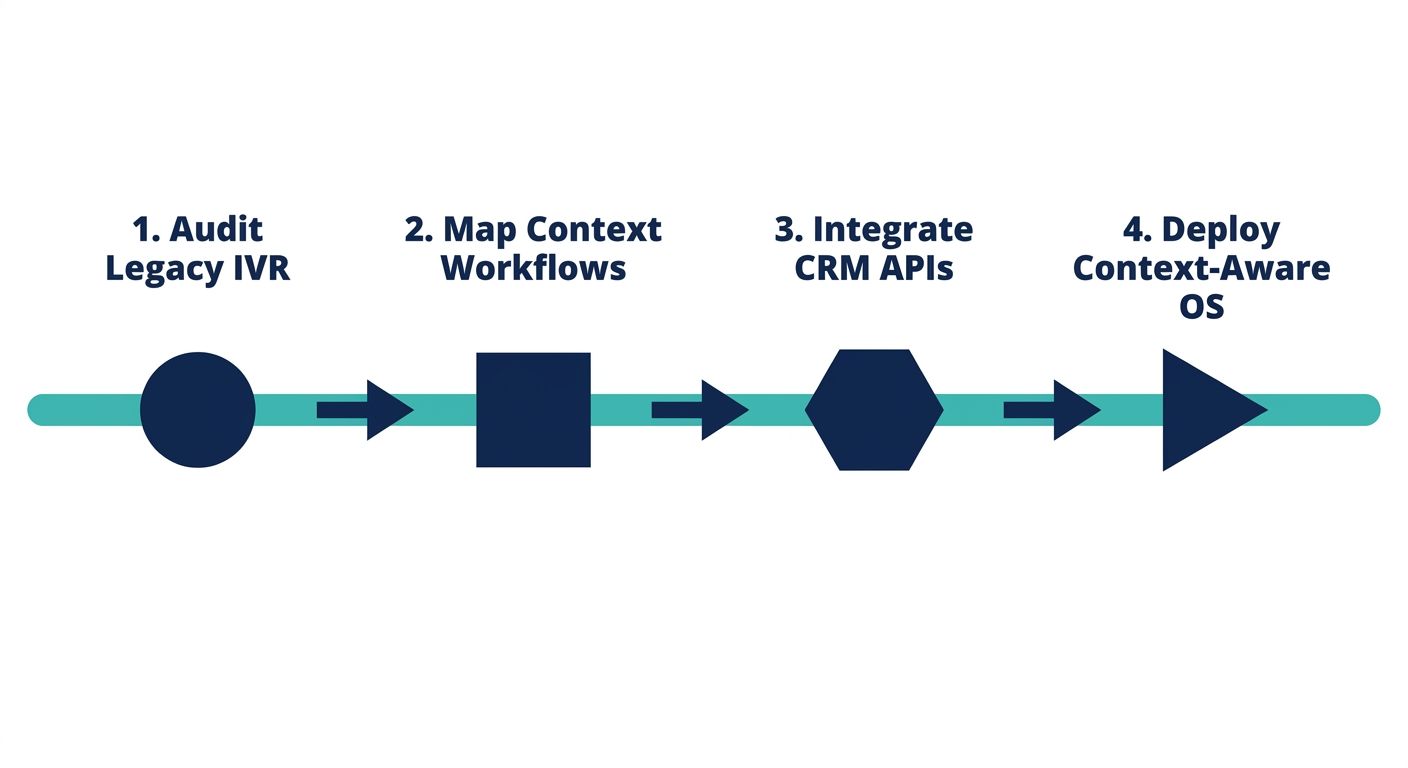
Transitioning from legacy Interactive Voice Response (IVR) systems or basic, context-free AI agents to a sophisticated Context-Aware Voice OS requires a structured, step-by-step migration blueprint. Enterprises must approach this implementation with a clear focus on data integration, security, and technical architecture to ensure the context layer functions optimally across the entire customer lifecycle.
Step 1: Technical Integration and Data Mapping
The foundation of a successful migration is mapping the enterprise's existing data infrastructure to the AI context layer. This involves identifying the primary sources of truth, such as CRMs, knowledge bases, and ticketing systems. Developers must establish secure, low-latency API connections between these repositories and the voice agent platform. During this phase, data must be structured and vectorized to ensure the semantic search algorithms can retrieve it efficiently during live voice calls.
Step 2: Designing the Set-Algebraic Pipeline
Once data streams are connected, technical teams must configure the context determination pipeline. This involves setting up the rules for metadata filtering, defining the parameters for deduplication, and establishing the ranking criteria specific to the business's industry. For example, a healthcare enterprise will require a highly strict metadata filter to comply with HIPAA regulations, while a retail enterprise might prioritize semantic search optimization to retrieve dynamic product catalogs accurately.
Step 3: Security, Compliance, and Context Persistence
Security must be embedded directly into the context layer. Enterprises must ensure that the context engine strips Personally Identifiable Information (PII) before sending payloads to the LLM, depending on the compliance requirements of the specific use case. Additionally, teams must define the rules for context persistence. They need to determine which conversational elements should be committed to short-term memory for the duration of the call, and which insights should be written back to the enterprise CRM for long-term lifecycle tracking.
Step 4: Continuous ROI Analysis and Optimization
Following deployment, the migration blueprint requires continuous monitoring of the Cost Per Qualified Outcome. Enterprises should analyze transcript logs to identify areas where the context layer successfully prevented STT hallucinations or retrieved critical data that expedited issue resolution. By continually refining the context arithmetic parameters based on live performance data, businesses can ensure their voice agents become increasingly efficient, driving sustained operational cost savings and delivering an unparalleled customer experience.
Conclusion
Addressing the question of what an AI context layer is for enterprise voice agents reveals the intricate, highly technical foundation required to make machine-generated voice interactions feel genuinely intelligent and human-like. It is not merely a memory bank, but an active, real-time computational engine that applies context arithmetic, semantic search, and set-algebraic pipelines to manage the inherent complexities of spoken language. As enterprises move beyond basic API implementations and seek true operational efficiency, prioritizing a platform with deep context handling mastery will be the defining factor in achieving a low Cost Per Qualified Outcome and a superior, context-aware customer lifecycle experience.




