
The Unstructured Data Dilemma in the Modern Enterprise
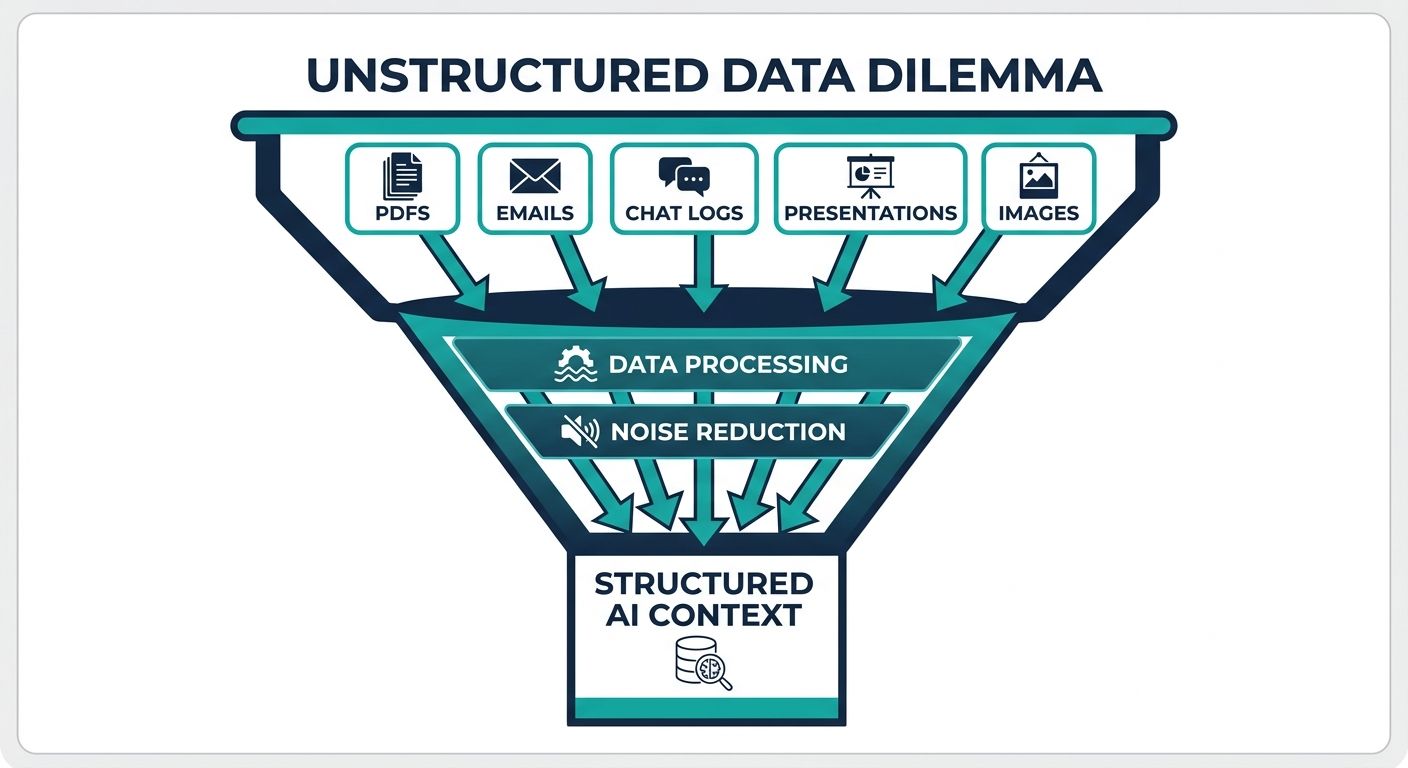
In today's fast-paced digital economy, organizations generate data at an unprecedented rate. However, industry research consistently reveals that upwards of eighty to ninety percent of this enterprise data is entirely unstructured. Unlike the neatly organized rows and columns found in relational databases, unstructured data takes the form of call transcripts, lengthy email threads, complex technical documentation, educational syllabi, multimedia files, and customer support chats. While this data is rich with intent, sentiment, and valuable business logic, it is inherently difficult for traditional software systems to parse, understand, and utilize.
Historically, businesses have attempted to manage this information using basic text extraction tools, Optical Character Recognition (OCR), or rigid regular expressions. These legacy approaches are fundamentally flawed because they merely identify strings of text without understanding the underlying meaning. Extracting a date or a monetary value from an invoice is a straightforward data extraction task; however, understanding the nuanced relationship between a customer's escalating frustration in a support ticket and their historical purchasing behavior requires a much deeper level of cognitive processing. This is where AI context extraction from unstructured data types becomes the critical differentiator for modern enterprises seeking to build intelligent, context-aware systems.
Defining AI Context Extraction
AI context extraction is a highly specialized process that goes far beyond simple keyword matching or entity recognition. It involves the use of advanced artificial intelligence, specifically Large Language Models (LLMs) and semantic processing engines, to read, analyze, and comprehend unstructured data in a way that mimics human understanding. The goal is not just to pull out specific words, but to extract the semantic relationships, temporal events, underlying intent, and operational metadata embedded within the raw information.
For example, when processing a complex syllabus or technical documentation file, AI context extraction identifies the hierarchical dependencies between different topics. It recognizes that a user must complete 'Module A' before attempting 'Module B,' extracting not just the text of the modules, but the chronological and conditional context connecting them. In the realm of conversational data, such as real-time audio transcripts from a sales call, context extraction involves identifying speaker intent, tracking sentiment shifts throughout the conversation, and isolating actionable commitments made by either party. By transforming messy, unstructured inputs into structured, verifiable semantic graphs, context extraction lays the essential groundwork for powering robust Retrieval-Augmented Generation (RAG) pipelines and real-time AI applications.
The Shortcomings of Generic LLMs and Standard RAG
As the demand for AI-driven insights has surged, many organizations have attempted to build applications using generic LLMs layered on top of standard vector databases. While these generic setups can provide impressive demonstrations, they frequently fail when deployed in rigorous enterprise environments. Top-ranking discussions often provide generic overviews of unstructured data extraction but consistently miss detailed, actionable insights into how an AI-native context management platform specifically processes and organizes verifiable context.
Generic LLMs suffer from severe limitations when dealing with massive troves of unstructured data. First, they are restricted by context windows; when a conversation or a document exceeds a certain token limit, the model simply 'forgets' earlier information. Second, standard RAG systems often rely on naive semantic search, retrieving chunks of text based purely on keyword similarity. This frequently leads to hallucinations, where the AI pieces together fragmented, out-of-context information to generate an inaccurate response. They lack a persistent memory layer that can track state across multiple sessions, and they do not inherently support the complex mathematical manipulation of context required to filter out noise.
Architectural Specifics: How AI-Native Context Extraction Works
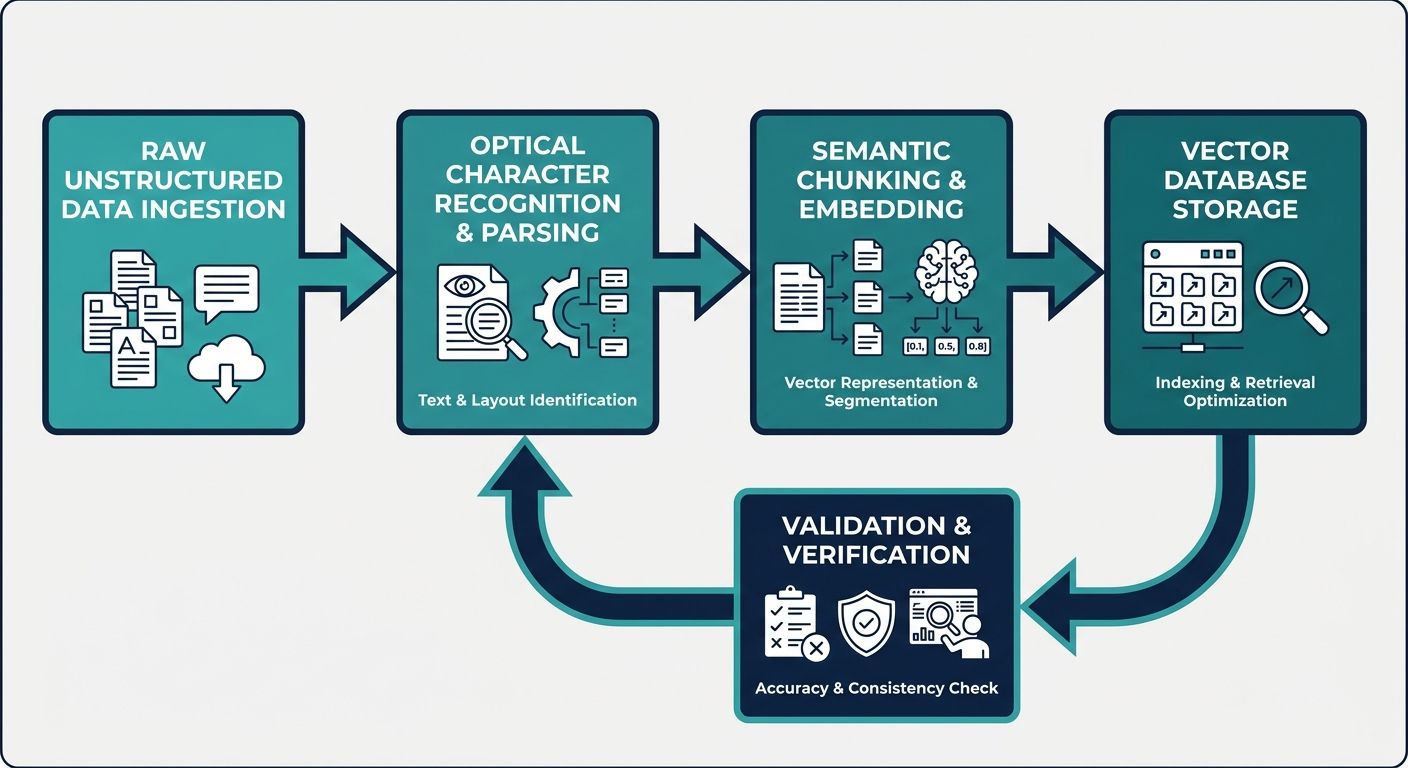
To overcome the limitations of generic models, a paradigm shift is required toward AI-native context management. This architectural approach is designed from the ground up to handle the specific intricacies of extracting context from diverse unstructured data types.
Semantic Ingestion and Intelligent Chunking
The first phase of the extraction pipeline is ingestion. Raw unstructured data formats - whether they are MDX documentation files, audio call transcripts, or complex PDFs - must be parsed and broken down into manageable pieces. However, instead of slicing a document arbitrarily every five hundred words, an AI context engine employs intelligent semantic chunking. It analyzes the linguistic structure of the document, ensuring that complete thoughts, paragraphs, or logical sections are kept intact. This preserves the local context of the information, ensuring that a critical sentence is not divorced from its surrounding explanatory text.
Vector Embeddings and High-Dimensional Semantic Spaces
Once the unstructured data is intelligently chunked, it is passed through an embedding model. This model translates human language into high-dimensional mathematical vectors. In this semantic space, concepts that are related in meaning are positioned closer together. This allows the AI engine to understand that a query about 'revenue growth' is contextually linked to unstructured text discussing 'sales increases' or 'financial expansion,' even if the exact keywords are never used.
The Power of Context Arithmetic
One of the most advanced architectural specifics in modern AI context extraction is the application of context arithmetic. Context arithmetic involves the mathematical manipulation of semantic vectors to refine, isolate, or combine meanings. Just as traditional mathematics allows you to add or subtract numerical values, context arithmetic allows an AI engine to add or subtract conceptual vectors. For example, if an AI is analyzing a massive corporate knowledge base, a developer might instruct the system to retrieve information related to 'cloud security' but mathematically subtract the vector for 'consumer pricing.' This context arithmetic effectively filters out irrelevant pricing models, providing the AI agent with highly refined, verifiable context that drastically improves the accuracy of the resulting generation.
Organizing Verifiable Context for Robust RAG
Extracting the context is only half the battle; organizing it so that it is instantly verifiable and retrievable by intelligent applications is the next critical hurdle. In a robust RAG architecture, extracted context is not merely dumped into a generic database. It is meticulously tagged with metadata, chronological timestamps, source attributions, and relationship mappings. This ensures that when an AI voice agent or a conversational chatbot retrieves information to answer a user's prompt, it can cite exactly where that context originated.
When managing complex enterprise knowledge, Alchemyst AI provides a powerful AI-Native Context Management solution that inherently specializes in parsing unstructured formats like dynamic documentation, syllabi, and sales transcripts. By leveraging custom AI models and a dedicated Memory service that persists user preferences and conversational history, the platform ensures context remains highly accurate, mathematically verifiable, and seamlessly retrievable across ongoing real-time sessions.
Building a Real-Time AI Context Engine API
For developers tasked with building the next generation of intelligent software, comprehensive API documentation and robust integration blueprints are absolutely essential. Current industry resources often lack concrete examples of how to actually build and integrate an AI context engine for demanding use cases like real-time voice agents. An effective API architecture for context extraction must be built for speed, scalability, and stateful interactions.
API Endpoints and Data Models
A well-architected context engine will feature dedicated endpoints for ingestion, extraction, and retrieval. A typical workflow might begin with a developer pushing unstructured audio transcripts to a POST /v1/context/ingest endpoint. The payload would include the raw text, speaker diarization tags, and session identifiers. The AI engine processes this data asynchronously, extracting key intents, sentiments, and action items.
Subsequently, when a real-time voice agent is actively conversing with a user, the application queries a GET /v1/context/retrieve endpoint. The request schema for this endpoint would include the current user's prompt, the session ID, and specific context arithmetic parameters to filter the response. The API responds with a structured JSON payload containing the most semantically relevant, highly-ranked context nodes, complete with verification metadata. This structured response is injected directly into the voice agent's prompt context window in milliseconds, enabling fluid, human-like conversations that are deeply informed by historical unstructured data.
Transforming Go-To-Market and Sales Automation
One of the most powerful applications of AI context extraction from unstructured data types lies in Go-To-Market (GTM) and sales automation strategies. Sales teams are continually inundated with unstructured data: hours of recorded discovery calls, complex email negotiations, fragmented CRM notes, and lengthy market research reports. Manually reviewing this data to extract actionable insights is incredibly time-consuming and prone to human error.
By integrating a dedicated context management engine into the sales tech stack, organizations can automate the extraction of critical deal intelligence. When a thirty-minute sales call concludes, the AI engine instantly ingests the raw unstructured audio transcript. It performs advanced context extraction to identify the buyer's pain points, technical objections, budget constraints, and agreed-upon next steps. This information is no longer buried in a lengthy text file; it is organized into structured, verifiable data points that automatically populate the CRM, trigger personalized follow-up emails, and alert sales managers to potential deal risks.
Furthermore, Alchemyst AI enables marketing and sales teams to synthesize vast amounts of market intelligence into cohesive content creation workflows. By extracting context from diverse industry reports, the platform can automatically generate highly targeted outbound messaging that resonates with specific buyer personas, dramatically increasing AI-driven efficiency across the entire GTM pipeline.
The Future of Context-Aware Intelligent Applications
As artificial intelligence continues to evolve, the ability to seamlessly bridge the gap between unstructured human data and structured machine intelligence will define the most successful enterprise software. We are moving away from stateless, transactional chatbot interactions and entering an era of persistent, context-aware AI applications. These systems will function as continuous digital collaborators that remember historical interactions, understand nuanced user preferences, and autonomously synthesize information across disparate data formats.
The foundational technology enabling this future is AI context extraction. By moving beyond generic text retrieval and embracing sophisticated architectures like semantic chunking, context arithmetic, and dedicated memory layers, developers can unlock the true value hidden within their enterprise's unstructured data. Whether the goal is to build an intelligent tutoring system capable of adapting to a student's evolving understanding of a complex syllabus, or a real-time voice agent that navigates high-stakes sales negotiations with perfect recall, mastering the extraction of verifiable context is the ultimate key to success.
In conclusion, treating unstructured data as a mere byproduct of business operations is no longer acceptable. It is a vast reservoir of potential intelligence waiting to be unlocked. Organizations that invest in specialized AI-native context management frameworks will not only solve the unstructured data dilemma but will fundamentally transform how they automate tasks, generate content, and interact with their customers at scale.
Ready to unlock the true potential of your unstructured data and build verifiable, context-aware AI applications that drive your Go-To-Market success?




