
The Imperative for a Multilingual AI Voice OS in Global Enterprise
In the rapidly evolving landscape of global customer engagement, enterprises face an unprecedented challenge: managing hundreds of thousands of daily customer calls across multiple languages without sacrificing resolution quality or skyrocketing operational costs. The traditional approach to this problem has relied heavily on outsourced offshore call centers or legacy conversational chatbots. However, for businesses managing high volume customer interactions, these conventional solutions have proven structurally inadequate. Legacy voice systems and basic chatbots lack the architectural depth to handle the nuances of spoken language context, resulting in frustrating, robotic-sounding experiences that ultimately damage brand reputation and inflate handling times.
Today, the focus has shifted toward robust, state-aware AI operating systems designed specifically for voice. A true multilingual AI voice OS is not merely a text-based language model retrofitted with speech-to-text (STT) and text-to-speech (TTS) capabilities. It is a comprehensive, enterprise-grade architecture that dynamically manages conversational state, executes real-time context retrieval across disparate languages, and seamlessly integrates with complex backend systems. For technical evaluators and developers, understanding the distinction between superficial prompt engineering and systemic context engineering is the critical first step in adopting a multilingual AI voice OS for high volume customer interactions.
This definitive guide serves as a comprehensive migration blueprint for businesses and developers seeking to implement a multilingual AI voice OS. We will explore the deep technical requirements of context arithmetic, the structural flaws of legacy voice AI, a step-by-step integration blueprint, and a modern framework for calculating return on investment (ROI) through a revolutionary pricing model: the cost per qualified outcome.
Why High Volume Customer Interactions Break Legacy Voice AI
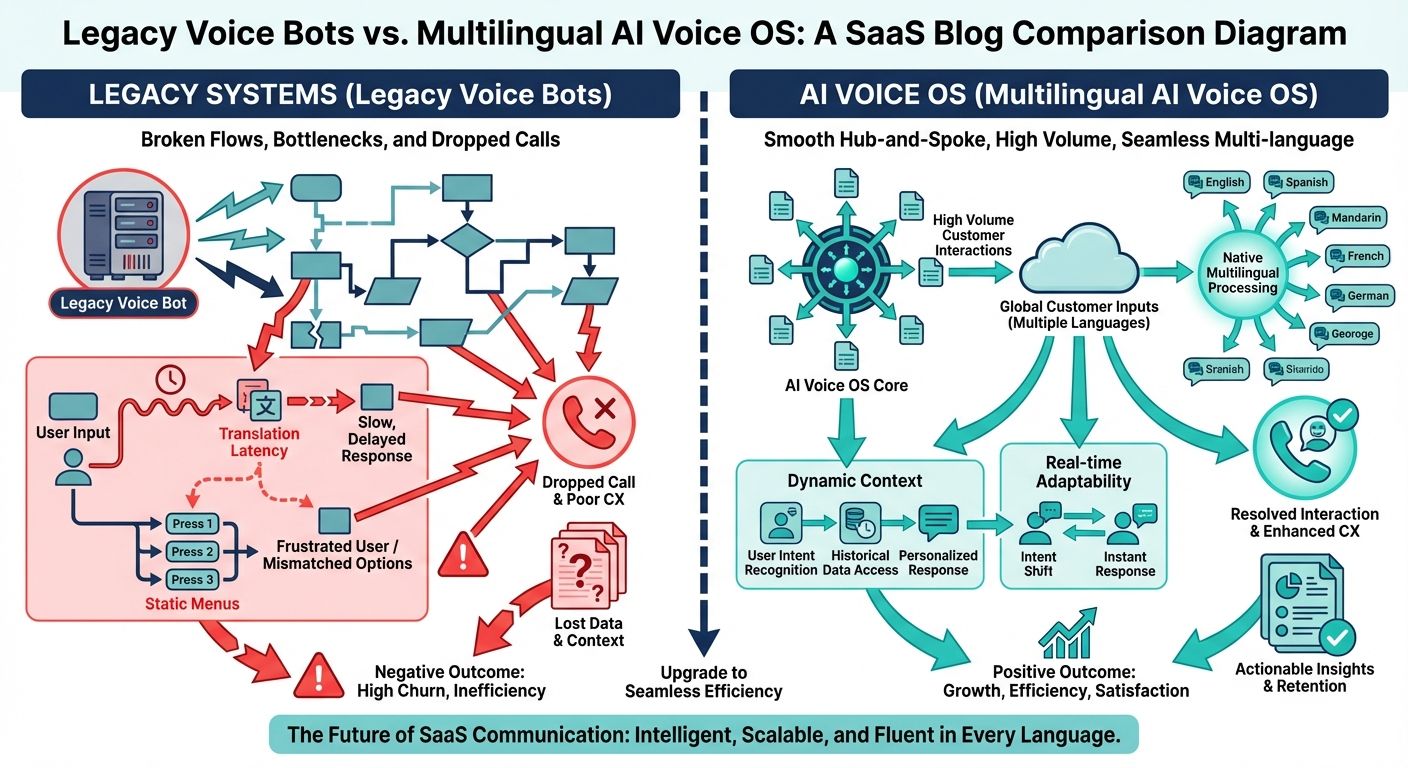
The marketplace is flooded with simple AI voice agents and platforms that promise multilingual capabilities. A quick review of top-ranking product lists often reveals solutions that employ a product-centric, API-first approach, prioritizing fast deployment over conversational depth. While these tools may suffice for low-volume, low-complexity tasks, they fundamentally collapse under the weight of high volume enterprise customer interactions. The root cause of this failure lies in the over-reliance on context-free architecture and rudimentary prompt engineering.
The Illusion of Prompt Engineering vs. True Context Engineering
Many legacy systems attempt to solve complex customer queries by loading massive, monolithic prompts into a large language model. In a multilingual environment, this approach is disastrous. Translating static prompts across dozens of languages leads to massive latency, semantic degradation, and context loss. Prompt engineering is a surface-level fix; it attempts to force a model to behave correctly without giving it structural awareness of the customer's historical state, active session variables, or relevant enterprise data.
Conversely, Context Engineering involves building a dedicated architectural layer that dynamically computes and injects only the most relevant, highly specific information into the conversational stream in milliseconds. In high volume settings, context engineering prevents the AI from hallucinating or forcing the customer to repeat themselves. It ensures that whether a customer is speaking Spanish, Mandarin, or English, the underlying state of their account and the specific resolution pathways are instantly available to the voice agent.
The Hidden Costs of Context-Free Agents
When an AI voice agent lacks a robust context layer, the financial repercussions are severe. Context-free agents operate amnesiacally. They ask redundant questions, fail to retrieve correct account details, and struggle to parse intent when customers code-switch or interrupt. This directly impacts the bottom line. Because most legacy AI voice agents operate on a per-minute or per-call pricing model, the longer an agent takes to stumble through a contextless conversation, the more the enterprise pays. In this flawed paradigm, the vendor profits from the inefficiency of their own AI. High volume deployments quickly see their ROI evaporate as context-free agents inflate average handle times (AHT) without delivering actual resolutions.
Core Architecture: Context Arithmetic for Voice
To solve the persistent problems of legacy deployments, pioneering systems like Alchemyst's Kathan engine utilize a computational process known as Context Arithmetic. This is not a simple vector database lookup; it is a highly sophisticated, set-algebraic pipeline designed to systematically determine relevant information for voice agents in real-time, regardless of the language being spoken.
Context Arithmetic treats information retrieval as a mathematical operation. When a customer speaks, the system must instantly parse the utterance, translate the semantic intent, and perform operations to intersect the current query with historical customer data, enterprise knowledge bases, and live API endpoints. This requires a meticulous architectural orchestration tailored specifically for developers and technical teams managing custom agents.
The Five-Stage Pipeline for Context Determination
The Kathan engine's architecture relies on a rigorous five-stage pipeline to ensure that the multilingual AI voice OS delivers hyper-relevant responses with sub-second latency:
- 1. Semantic Similarity Search: The system captures the STT output and immediately vectorizes it, performing a cross-lingual semantic search. Because the embeddings are language-agnostic, a query in French can instantly retrieve relevant resolution protocols written in English or German from the central knowledge graph.
- 2. Metadata Filtering: Pure semantic search often returns false positives. The pipeline applies rigid metadata filters based on the active conversational state—such as the user's account tier, geographic location, and current progress in the troubleshooting flow.
- 3. Set-Algebraic Deduplication: In high volume interactions, overlapping data points can confuse the LLM. The context arithmetic engine uses set theory (unions, intersections, differences) to strip out redundant information, ensuring the payload remains lightweight and precise.
- 4. Dynamic Ranking: The remaining context shards are ranked not just by keyword relevance, but by conversational urgency. A critical account alert will rank higher than a general FAQ response, steering the multilingual voice agent to address high-priority issues first.
- 5. Context Injection: Finally, the optimized, deduplicated context is injected into the prompt dynamically. This localized, highly constrained payload ensures the text generation phase is fast, accurate, and perfectly aligned with the customer's intent.
The Definitive Migration Blueprint for Enterprises
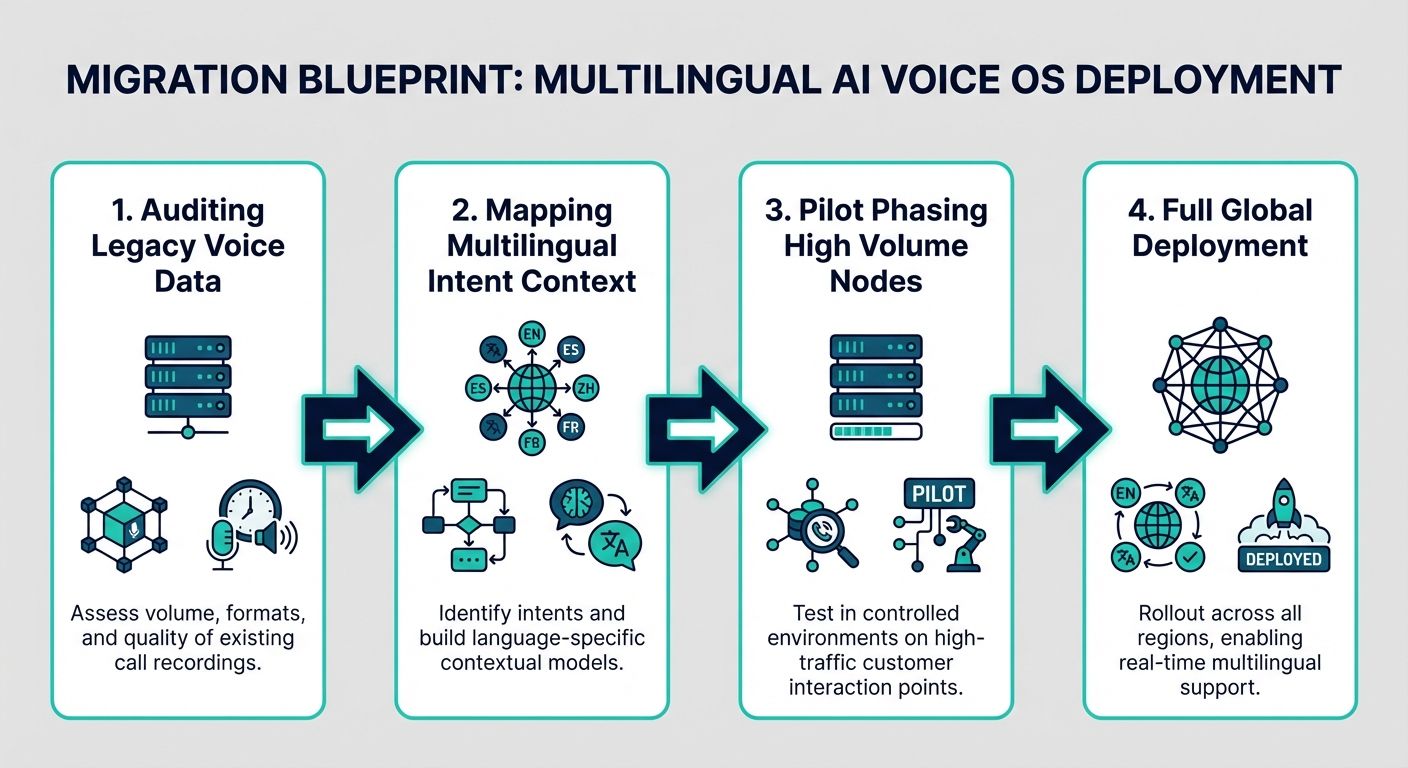
Transitioning from legacy chatbots or human-operated call centers to a robust multilingual AI voice OS requires a structured migration blueprint. Top-ranking pages often provide generic cost savings advice, but they severely lack detailed technical integration blueprints. For enterprise developers and IT leaders, migration must be treated as an architectural overhaul, demanding strict adherence to data migration protocols, security standards, and seamless STT/TTS alignment.
Phase 1: Technical Integration and STT/TTS Alignment
The foundation of a successful AI Voice OS migration is the integration of the telephony layer with the STT and TTS engines. Unlike text chatbots, voice agents must operate within extreme latency constraints. Human conversational tolerance for pauses is roughly 500 to 700 milliseconds. When dealing with multilingual high volume interactions, processing STT, executing context arithmetic, generating a response, and synthesizing TTS must happen within this window. Developers must utilize direct SIP trunking and WebRTC integrations to bypass legacy telephony delays. Furthermore, selecting STT and TTS models natively optimized for code-switching—where a user fluidly shifts between two languages—is critical for global deployments.
Phase 2: Data Migration and Knowledge Graphing
You cannot simply upload PDF manuals into a vector database and expect enterprise-grade voice performance. Phase 2 requires transforming flat, unstructured enterprise data into a dynamic knowledge graph. This involves chunking data purposefully, tagging it with rich metadata, and mapping relationships between different standard operating procedures. During this phase, security is paramount. The migration blueprint must include strict data anonymization protocols to ensure Personally Identifiable Information (PII) is masked before it ever hits the semantic search index. This ensures compliance with GDPR, CCPA, and global data sovereignty laws while maintaining the context necessary for high volume customer interactions.
Phase 3: Developer Control and Self-Service Access
A critical gap in many enterprise solutions is the lack of developer autonomy. A true AI Voice OS must offer an open dashboard and direct self-service platform access. Enterprises need robust developer communities and events resources to continuously train their teams. By providing deep API access to the context layer, developers can fine-tune the set-algebraic pipeline, adjust the weighting of metadata filters, and build custom webhooks that trigger backend physical actions (such as processing a refund or updating a CRM) directly from the voice interface.
Rethinking the Pricing Model: Cost Per Qualified Outcome
A comprehensive migration blueprint must also address the financial mechanics of adopting a multilingual AI voice OS. The industry standard has long been per-minute, per-call, or per-seat pricing. This is a fundamentally misaligned incentive structure. When evaluating Voice AI pricing models, businesses must recognize the hidden costs of these metrics. As previously noted, context-free agents artificially inflate talk time. If you are paying per minute, you are penalizing your business for the AI's incompetence.
Why Per-Minute Pricing is Flawed
In high volume customer interactions, a few extra seconds per call compound into millions of dollars in wasted operational expenditure. Per-minute billing encourages vendors to utilize slower STT models, ignore conversational latency, and deprioritize swift issue resolution. It transforms the AI from a tool of efficiency into a meter continuously draining enterprise budgets. It creates an adversarial relationship between the enterprise seeking swift resolutions and the vendor profiting from extended handle times.
Defining the Qualified Outcome
The future of AI Voice OS pricing is the Cost Per Qualified Outcome (CPQO) model. Under this framework, businesses do not pay for the time the AI spends talking; they pay only when the AI successfully achieves a predefined conversational goal. A qualified outcome might be defined as successfully processing a return, accurately capturing a lead's qualification details, or resolving a Tier 1 technical support ticket without human escalation. This model forces the AI vendor to focus entirely on architectural excellence. To be profitable under a CPQO model, the vendor must leverage advanced context arithmetic, eliminate latency, and utilize state-aware conversational management to solve the customer's problem as quickly and accurately as possible.
Calculating ROI for High Volume Voice Deployments
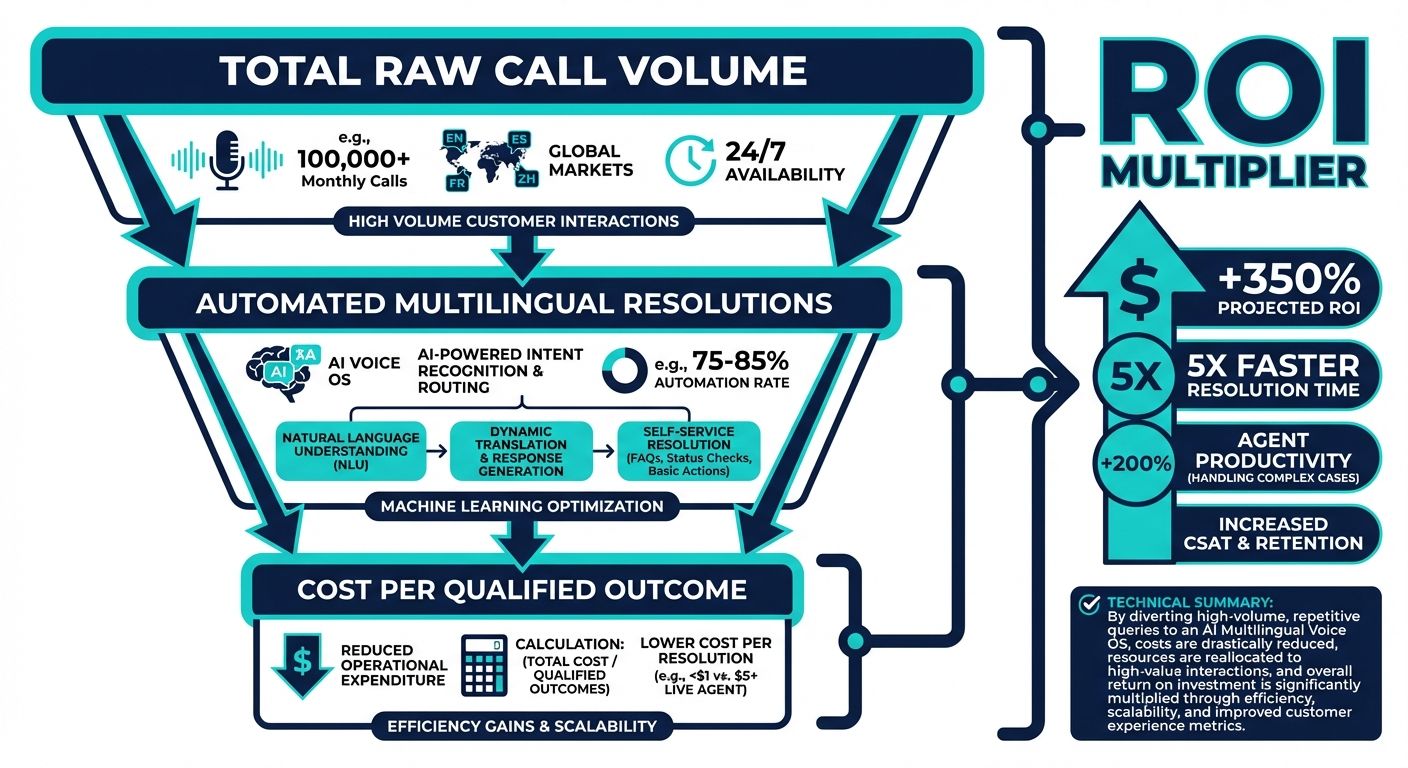
Beyond generic cost savings, enterprises require a structured framework for calculating the Return on Investment (ROI) of a multilingual AI voice OS. When moving to a CPQO model and deploying context-aware architecture, the financial benefits extend far beyond simply reducing human headcount.
Operational Savings vs. Revenue Generation
The ROI calculation begins with operational savings. By deploying a multilingual AI voice OS that utilizes context engineering, enterprises drastically reduce their Average Handle Time (AHT) and increase their First Call Resolution (FCR) rates. However, a truly robust AI voice agent also transitions the contact center from a cost center to a revenue-generating asset. Because the system can seamlessly handle hundreds of thousands of concurrent calls across different languages, businesses can launch proactive outbound campaigns—such as renewal reminders, cross-selling initiatives, and multilingual debt collection—at a fraction of the traditional cost.
A Structured Framework for ROI Assessment
To accurately calculate ROI, organizations should evaluate the following specific metrics before and after deployment:
- Escalation Deflection Rate: The percentage of calls successfully resolved by the AI without requiring routing to a human agent. Context arithmetic significantly increases this rate by providing the AI with deep systemic knowledge.
- Infrastructure Cost Reduction: The elimination of redundant legacy software licenses, localized PBX hardware, and fragmented translation services.
- Customer Lifetime Value (CLTV) Retention: By eliminating robotic, frustrating interactions and offering immediate, context-aware multilingual support, enterprises reduce customer churn. Retaining a high-value customer through superior voice experiences directly impacts the top line.
- Outcome Achievement Cost: Comparing the historical human cost of resolving a specific ticket type against the fixed CPQO rate of the AI Voice OS.
Overcoming Unique Challenges in Spoken Language Context
To truly appreciate the necessity of advanced systems like the Kathan engine, technical evaluators must understand the unique challenges inherent in spoken language context, particularly in multilingual, high-volume environments.
Handling Interruptions and Code-Switching
Human speech is inherently messy. Callers interrupt, change their minds mid-sentence, and frequently mix languages (code-switching). A conventional chatbot will reset its conversational flow when interrupted, forcing the user to start over. A state-aware multilingual AI voice OS maintains a continuous temporal state map. If a caller interrupts to provide new information, the context arithmetic engine immediately recalculates the metadata filtering and dynamically ranks the new priority, seamlessly adapting the conversation without dropping the overarching goal.
State-Aware Call Management
High volume interactions demand memory. If a customer calls back three times in a week, the AI must instantly recognize their state, bypassing introductory triage and jumping directly to the ongoing issue. This requires deep integration between the voice OS and the enterprise CRM. The architectural requirement for a context layer ensures that real-time processing of this historical data happens flawlessly. Through robust developer tools and open platform access, engineering teams can configure exactly how long conversational state is maintained and what security parameters govern the retrieval of past interactions.
Conclusion: The Future of Global Customer Service
Deploying a multilingual AI voice OS for high volume customer interactions is no longer a futuristic luxury; it is an operational necessity for global enterprises. Relying on basic AI voice agents, legacy chatbots, and inherently flawed per-minute pricing models will only lead to inflated costs and degraded customer experiences. By embracing advanced context engineering, leveraging the computational power of context arithmetic, and migrating to a cost per qualified outcome pricing model, businesses can radically transform their customer lifecycle.
The definitive migration blueprint provided here underscores the importance of technical rigor, data migration, and developer autonomy. As systems like Alchemyst's Kathan engine continue to redefine what is possible in voice architecture, enterprises that adopt these comprehensive, state-aware operating systems will secure a massive competitive advantage, delivering unparalleled, localized support to millions of customers worldwide.




