
The Paradigm Shift: From Prompt Engineering to Context Engineering
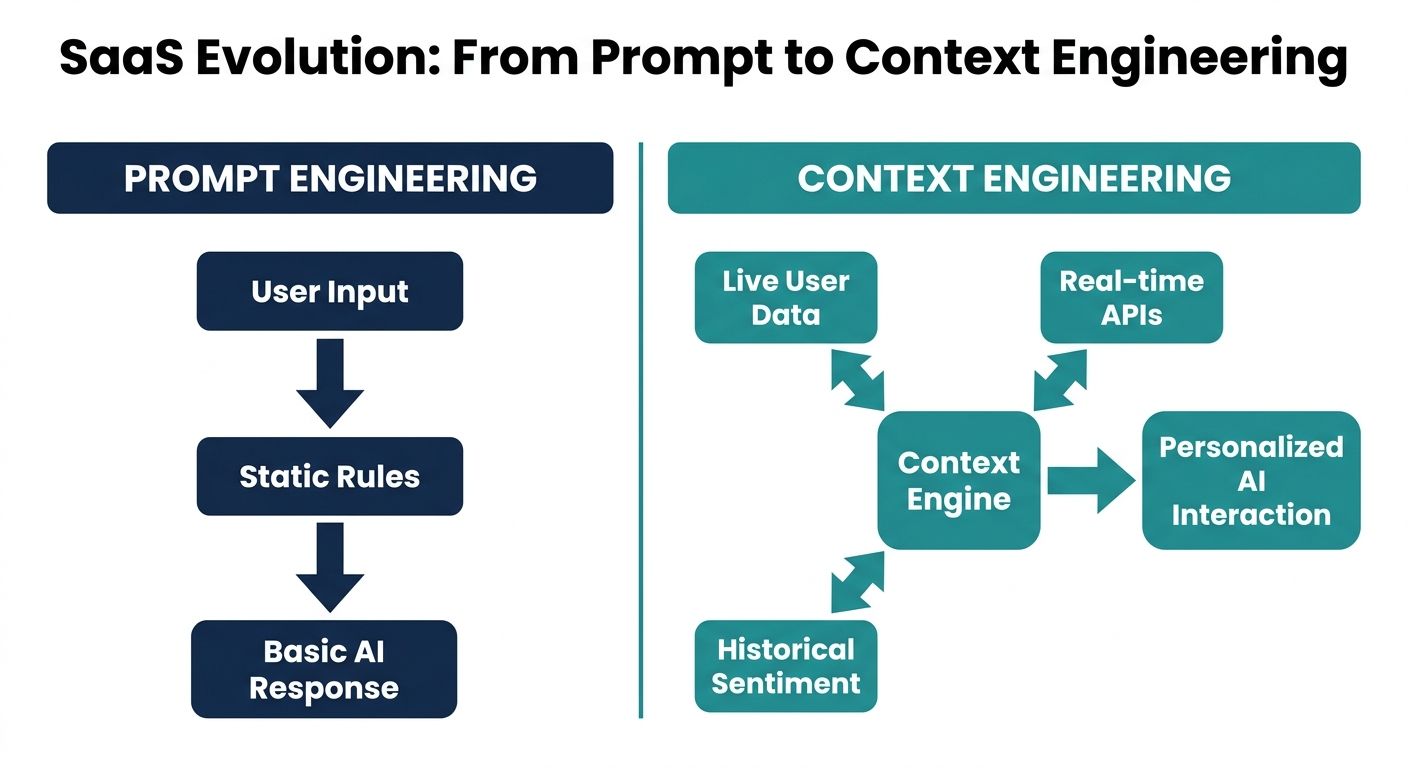
As enterprise conversational AI platforms evolve beyond simple text generation into complex, multi-turn dialogue systems, developers are hitting the limitations of traditional prompt engineering. Prompt engineering focuses on instructing a Large Language Model (LLM) on how to behave. In contrast, context engineering is the systematic, algorithmic process of determining exactly what information the model needs to process at any given microsecond to deliver accurate, non-robotic, and goal-oriented responses.
Many current implementations treat context as a static injection of a system prompt combined with a rudimentary sliding window of chat history. However, for true conversational AI—especially voice-first AI systems—this approach results in latency spikes, high token costs, and contextual amnesia. Top-ranking guides often provide generic definitions of context engineering for broad AI agents. In this technical primer, we will explore the concrete architectural patterns, the concept of context arithmetic, and the voice-specific implementation strategies required to build enterprise-grade conversational AI platforms.
Why Top Platforms Fail: The Generic Context Problem
Before diving into the implementation details, it is crucial to understand the structural flaws of previous-generation systems. The majority of enterprise platforms utilize context-free agents. These systems rely heavily on intent-matching or basic vector search without a structural understanding of conversational state.
When businesses deploy these context-free agents, they inadvertently inflate their expenses. Common pricing models in the Voice AI industry rely on per-minute, per-call, or per-seat structures. A context-free agent that constantly asks users to repeat information, or misinterprets ambiguity because it lost the conversational thread, extends call durations artificially. This hidden cost underscores the necessity of measuring ROI through the lens of cost per qualified outcome. A context-aware system reduces call duration, handles complex multi-turn logic seamlessly, and dramatically improves this ROI metric by focusing on successful resolution rather than mere interaction time.
Architectural Patterns for Context Engineering
Implementing context engineering requires a shift from linear API calls to a dynamic, event-driven architecture. At the core of a modern conversational AI platform is the Context Engine, a middleware layer that sits between the user interface (voice/text), the enterprise data systems (CRM/ERP), and the LLM infrastructure.
Context Arithmetic: A Set-Algebraic Approach
To systematically determine the relevant information for a voice agent, developers should adopt what Alchemyst's Kathan engine categorizes as context arithmetic. This is a computational process that treats context retrieval and management as a set-algebraic pipeline. Instead of simply concatenating strings, the engine calculates the intersection, union, and difference of various context sets (user profile, situational data, dialogue history, and enterprise knowledge) to construct an optimal prompt payload.
The Five-Stage Pipeline for Context Determination
Implementing context arithmetic involves building a rigid, highly-optimised five-stage pipeline. This pipeline executes in milliseconds prior to every LLM inference call.
- 1. Information Retrieval and Semantic Similarity Search: The system captures the user's latest utterance and converts it into a high-dimensional vector embedding. This vector is queried against a Vector Database (like Pinecone or Weaviate) to retrieve semantically similar chunks of knowledge. However, relying on semantic similarity alone leads to hallucinations if the retrieved context is outdated or tangentially related.
- 2. Metadata Filtering: To restrict the vector search space, the pipeline applies strict metadata filtering. This includes deterministic constraints such as the current timestamp, the user's specific account ID, or their geographical location. This stage ensures that a customer asking 'What is my current balance?' only retrieves context linked strictly to their encrypted CRM entity.
- 3. Dynamic Dialogue State Extraction: The system must maintain an internal representation of the conversation state. This involves tracking active intents, slot filling statuses, and emotional sentiment. If a user says 'Actually, change that to tomorrow,' the state extractor maps 'that' to the most recent active entity in the short-term memory buffer.
- 4. Deduplication: In multi-turn conversations, the same context chunks are often retrieved repeatedly, eating up token limits and confusing the LLM with redundant data. The deduplication stage removes overlapping information payloads, ensuring the context window remains lean and highly concentrated with net-new or immediately relevant information.
- 5. Context Ranking and Assembly: Finally, the retrieved pieces of context are scored and ranked. The ranking algorithm prioritizes recency (short-term memory), relevance (semantic score), and critical system instructions. The highest-scoring elements are assembled into the final prompt payload and sent to the LLM.
Voice-Specific Implementation Challenges
Implementing context engineering for chat platforms is fundamentally different from implementing it for voice platforms. Voice-first OS integrations introduce real-time constraints and acoustic ambiguities that text-based platforms never encounter. Top-tier engines like Alchemyst's Kathan are designed specifically to handle these voice-centric anomalies.
Handling STT (Speech-to-Text) Inaccuracies
In a voice agent, the input is never perfectly clean. STT engines often mishear proper nouns, acronyms, or industry jargon. If a context engine takes these transcripts literally, the semantic search will fail. Implementations must include phonetic fuzzy matching within the retrieval pipeline and utilize conversational context to auto-correct transcripts before they hit the vector database. For example, if the active conversational context is 'insurance policies', an STT output of 'deductible' must be prioritized over acoustically similar but contextually irrelevant words.
Managing Interruptions and Barge-ins
Voice interactions are highly non-linear. Users will frequently interrupt the agent (a barge-in). When an interruption occurs, the context engine must instantly truncate the agent's expected output, log the exact point at which the user interrupted, and append the barge-in utterance. The context pipeline must immediately recalculate the active intent. If an agent is reading a list of options and the user interrupts with 'The second one', the context engine must mathematically map 'second one' to the exact item the Text-to-Speech (TTS) engine was vocalizing at the millisecond of interruption.
Latency and the Context Window
Voice agents require a total round-trip time (STT + Context Pipeline + LLM generation + TTS) of under 800 milliseconds to feel natural. Heavy context engineering can introduce severe latency if not optimised. Developers must implement parallel processing: while the user is still speaking, the system should pre-fetch CRM data and warm up vector searches based on partial STT streams, finalizing the context assembly only when endpointing (silence detection) is triggered.
Integrating RAG and CRM Data into the Conversation Loop
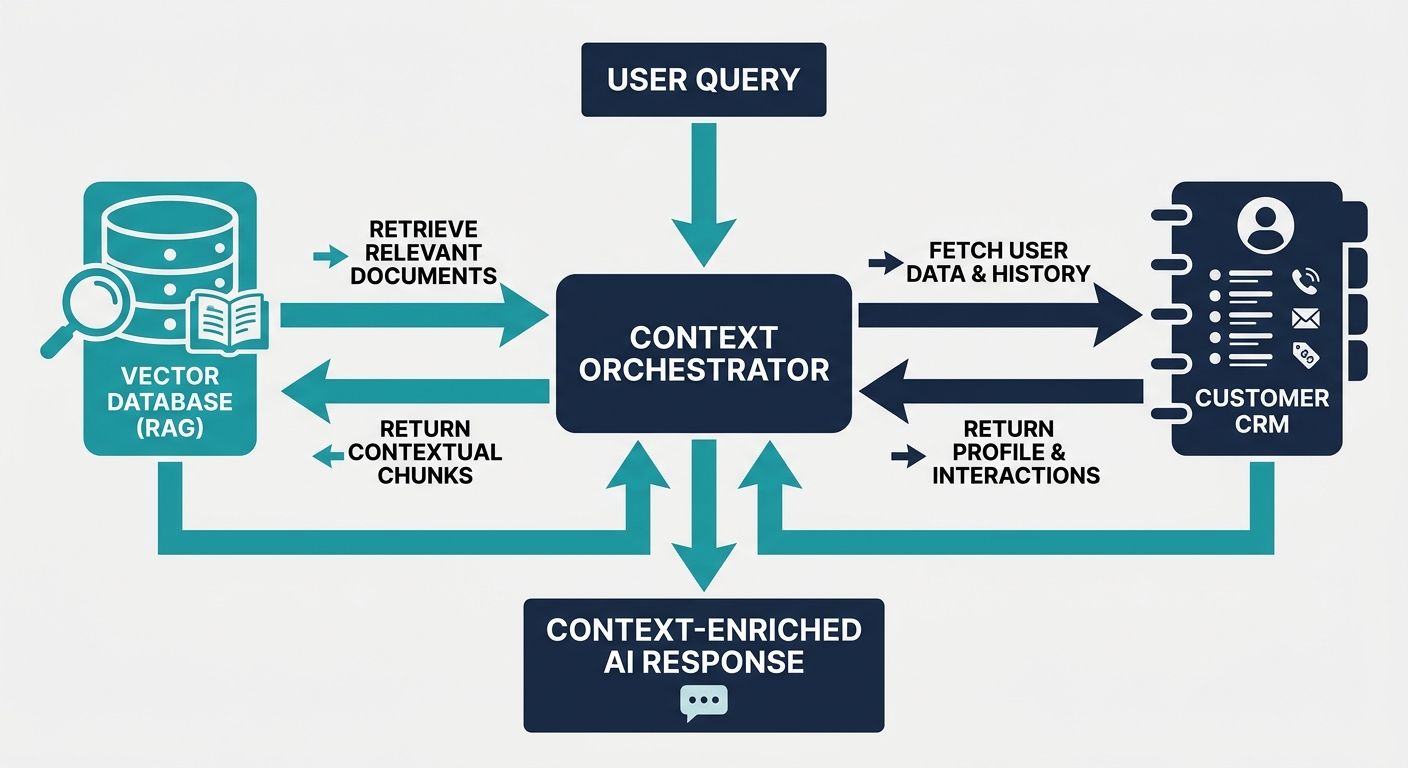
Retrieval-Augmented Generation (RAG) is the backbone of enterprise context engineering. However, generic RAG architectures fail in complex dialogue flows because they treat every query in isolation. A conversational AI platform requires an architecture where RAG is continuously modulated by the conversational state.
To implement this at the code and architectural level, developers must construct a robust State Management Object. This object is dynamically updated on every turn. Consider the following architectural data structure concept:
- Short-Term Memory Buffer: Stores the exact transcripts of the last 5-10 turns. Used for immediate pronoun resolution and contextual continuity.
- Long-Term Memory Graph: Stores summarized facts about the user from previous sessions. Implemented via a Knowledge Graph rather than a flat vector database to understand relationships (e.g., 'User owns Product X, Product X requires Update Y').
- CRM API Context: Real-time data payloads fetched via REST/GraphQL from systems like Salesforce or HubSpot. This must be injected as structured JSON within the LLM's system prompt to ensure absolute factual accuracy regarding account statuses.
When the user speaks, the Context Engine dynamically generates a specific retrieval query based on the Short-Term Memory Buffer, fetches the exact vector embeddings, cross-references them against the Long-Term Memory Graph, and validates the output against the CRM API Context. This is the essence of true context arithmetic.
The Definitive Migration Blueprint for AI Voice OS
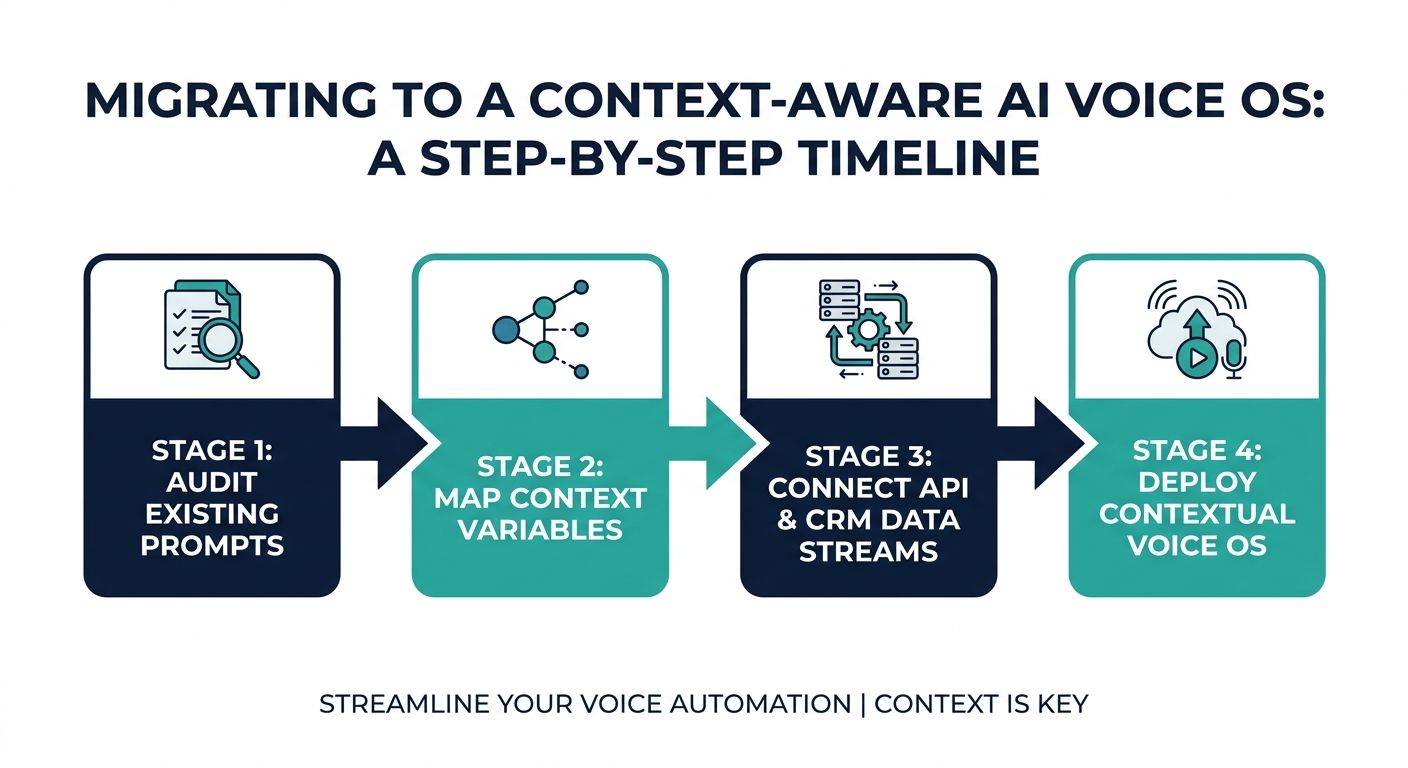
Many enterprises are stuck with legacy IVR systems or basic chatbots because they lack a comprehensive migration blueprint. Transitioning to a context-aware AI Voice OS requires structured planning, technical integration, and rigorous security measures. Here is a step-by-step implementation guide.
Step 1: Data Migration and Knowledge Structuring
Before any context engine can operate, enterprise data must be cleaned and vectorized. Do not blindly dump PDF manuals into a vector database. Implement hierarchical chunking strategies. Document structures must retain metadata (headers, section titles, product IDs) so the metadata filtering stage of your context pipeline functions correctly. Extract key entities and relationships to build a foundational knowledge graph.
Step 2: Designing the Event-Driven Architecture
Transition from synchronous webhook architectures to asynchronous, event-driven microservices. Utilize message brokers (like Kafka or RabbitMQ) to handle real-time streaming audio. The STT service should stream partial transcripts to the Context Engine, allowing it to begin preliminary context retrieval before the user finishes speaking.
Step 3: Implementing Security and Data Redaction
Enterprise conversational AI deals with PII (Personally Identifiable Information) and PCI (Payment Card Industry) data. Context engineering must include a redaction layer. Before user utterances enter the semantic search phase or are sent to the LLM, a local, deterministic NLP model must mask sensitive data (e.g., replacing credit card numbers with tokens). The context payload returned to the TTS engine can unmask these tokens securely.
Step 4: Real-World Testing and Simulation
Context-aware agents cannot be tested like traditional software. Developers must employ LLM-as-a-Judge frameworks to simulate thousands of conversational paths. Evaluate the agent's ability to maintain context over 20+ turns, handle aggressive barge-ins, and gracefully recover from ambiguous STT inputs. Monitor the exact context payloads generated to ensure the deduplication and ranking stages are functioning optimally.
Step 5: ROI Tracking and Continuous Optimisation
Post-deployment, shift analytics away from generic metrics. Track the 'cost per qualified outcome'. Monitor how often the context engine successfully retrieves the correct CRM data on the first attempt without asking the user clarifying questions. Analyze the latency introduced by each stage of the context arithmetic pipeline and optimise database indexes accordingly.
Conclusion: The Future of Context-Aware AI
Implementing context engineering for conversational AI platforms is far more complex than wrapping an API call around a prompt. It requires a deep, architectural commitment to managing conversational state, integrating disparate data streams, and orchestrating split-second decision pipelines. Platforms that rely on context-free agents will continue to suffer from hallucination, poor user experiences, and inflated operational costs.
By adopting advanced methodologies like context arithmetic, set-algebraic pipelines, and voice-specific real-time optimizations, developers can build AI agents that truly understand the user. This level of implementation moves conversational AI from a novelty to a mission-critical enterprise asset, driving genuine ROI and transforming the entire customer lifecycle.




