
Bridging the Demo-to-Deployment Gap in AI Agent Infrastructure
The transition from a compelling proof-of-concept to a robust, enterprise-grade deployment is the most treacherous phase in AI development. While lightweight frameworks make it trivial to spin up a local conversational agent, designing a true reference architecture for production-ready AI agent infrastructure requires a profound shift in engineering philosophy. It is no longer just about prompt engineering; it is about building resilient, secure, and scalable systems capable of real-time context management, robust MLOps, and deterministic outcomes.
Today, top-ranking resources often lack prescriptive, technical guidance on concrete architectural patterns. They gloss over the specific MLOps tooling tailored for AI agent lifecycle management, deployment, monitoring, and versioning. Furthermore, there is a distinct gap in addressing the unique complexities of voice AI agents, which require ultra-low latency, streaming architectures, and specialized human-in-the-loop (HITL) strategies. This guide provides a definitive migration blueprint and reference architecture for production-ready AI agent infrastructure, focusing on bridging the demo-to-deployment gap with advanced context engineering.
Core Pillars of Production-Ready Agentic Architecture
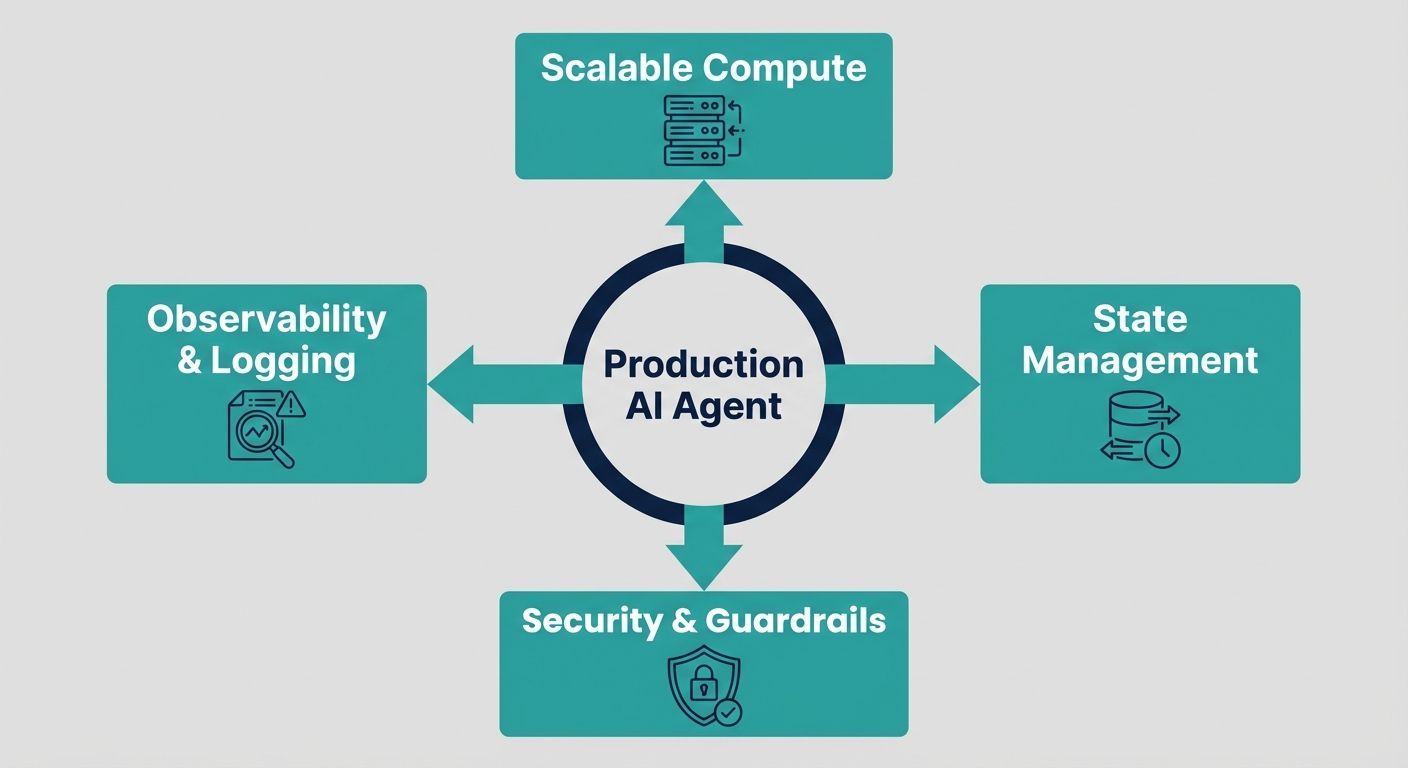
A production-ready infrastructure must support autonomous decision-making while enforcing strict guardrails. Unlike traditional microservices, AI agents operate non-deterministically, interacting dynamically with external environments, APIs, and users. To manage this safely, the architecture must be founded on three core pillars: Context Engineering, MLOps for Agents, and Enterprise Governance.
1. MLOps Tooling and Lifecycle Management
Standard software CI/CD pipelines are insufficient for AI agents. In a production environment, you are not just versioning code; you are versioning system prompts, retrieval strategies, tool schemas, and underlying foundational models. A robust MLOps stack for agents includes specialized deployment, monitoring, and versioning platforms. Infrastructure must support shadow deployments, where a new agent version processes live traffic asynchronously to evaluate its tool-calling accuracy before taking over the primary traffic routing. Furthermore, specialized monitoring observability platforms are critical to trace an agent's reasoning steps, API latency, and token consumption per invocation.
2. Security, Governance, and Human-in-the-Loop (HITL)
Security for AI agents extends beyond network perimeters. Because agents can autonomously trigger external actions (like database writes or API calls), strict Role-Based Access Control (RBAC) must be applied at the tool level. The infrastructure must enforce execution guardrails, ensuring that high-stakes actions require explicit human validation. For voice AI agents in particular, a robust Human-in-the-Loop strategy is critical. If a voice agent encounters an out-of-domain query or detects high customer frustration via sentiment analysis, the architecture must seamlessly hand off the conversational state to a human operator without dropping the call.
Data Pipelines and Context Engineering: The Alchemyst Advantage
The defining characteristic of a successful enterprise AI agent is not the size of its underlying LLM, but the quality of its context. While many platforms provide a configurable API for developers to build basic agents, they offload the immense burden of context management onto the user. This often results in 'context-free agents' that hallucinate, loop indefinitely, or fail to resolve complex customer issues.
Moving Beyond Prompt Engineering to Context Engineering
Prompt engineering alone cannot sustain enterprise voice AI. A reference architecture for production-ready AI agent infrastructure must incorporate Context Engineering. This involves dynamically assembling the exact knowledge, conversational history, and situational parameters required for the agent to make an optimal decision at any given millisecond. This is where Alchemyst's Kathan engine distinguishes itself from basic API-first platforms.
The Context Arithmetic Pipeline
At the heart of a truly robust AI voice OS is a systematic, computational process for determining relevant information. The Kathan engine utilizes a highly optimized five-stage 'context arithmetic' pipeline to systematically resolve context prior to LLM generation. This set-algebraic pipeline guarantees that voice agents operate with deterministic knowledge retrieval:
- Semantic Similarity Search: The pipeline begins by converting incoming voice queries (transcribed to text) into high-dimensional vector embeddings, searching vector databases to retrieve conceptually related enterprise knowledge.
- Metadata Filtering: To prevent retrieving irrelevant but semantically similar documents, strict metadata filters (such as tenant ID, user role, and temporal validity) are applied to narrow the search space.
- Deduplication: The system computationally removes redundant data chunks retrieved from overlapping knowledge bases, ensuring the context window remains highly efficient and token-optimized.
- Ranking: The remaining chunks are scored and re-ranked using cross-encoder models to prioritize the most immediately actionable information for the agent.
- Set-Algebraic Pipeline: Finally, logical set operations (unions, intersections, differences) combine dynamic data (e.g., live CRM API responses) with static knowledge base retrieval, forming a perfectly bounded context block for the LLM.
Detailed Blueprint: Voice AI Infrastructure Components

Deploying a voice-native AI agent introduces structural complexities that text-based chatbots bypass. Voice requires real-time processing, handling interruptions, and natural prosody. The reference architecture must be optimized for sub-500 millisecond latency from speech-to-speech.
Streaming Orchestration and State Management
To eliminate dead air during calls, the orchestration layer must support fully asynchronous, chunked streaming. As the user speaks, a streaming Speech-to-Text (STT) model processes the audio. The orchestration engine—often built on custom state machines rather than generic frameworks—must begin predicting intents and pre-fetching API data before the user even finishes their sentence. Once the LLM begins generating a response, the tokens must be streamed directly to a Text-to-Speech (TTS) engine, which synthesizes audio in chunks and streams it back to the telephony provider (like Twilio or Plivo). State management is handled by ultra-fast in-memory datastores (like Redis), maintaining the conversational graph and context arithmetic state across the distributed system.
Storage: Vector Databases and Caching
Production environments demand scalable vector databases (such as Pinecone, Qdrant, or Milvus) capable of executing sub-millisecond similarity searches across billions of embeddings. To minimize LLM latency and reduce inference costs, the architecture must implement a semantic caching layer. If a user asks a question that is semantically identical to a previously answered query (e.g., 'What are your business hours?' vs 'When do you open?'), the cache immediately serves the pre-computed response, bypassing the LLM entirely.
Agent-Specific Monitoring and Telemetry
Generic APM tools cannot debug AI agents. The infrastructure requires telemetry that traces the 'Agentic Loop'. When a user speaks, the telemetry must log the STT transcription latency, the context arithmetic retrieval time, the prompt compilation time, the LLM Time-to-First-Token (TTFT), the tool execution latency, and the TTS synthesis time. Without this granular observability, debugging a 2-second delay in a voice call becomes practically impossible.
Cost Analysis for Production Scaling
One of the most critical gaps in top-ranking architectural guides is the absence of specific cost analysis for production scaling. Transitioning from POC to production can result in massive, unexpected cloud and API expenditures if the infrastructure is not properly optimized.
Hidden Costs in Voice AI Deployments
Voice AI pricing models, particularly in emerging markets like India, are fraught with hidden costs. Many competitors utilize a per-minute, per-call, or per-seat pricing structure. While this seems straightforward, it fundamentally misaligns incentives. 'Context-free agents' built on brittle infrastructure tend to ask clarifying questions repeatedly, stall while retrieving data, or loop through inefficient logic. This inflates the call duration, driving up per-minute costs without successfully resolving the customer's intent. Businesses end up paying for compute time rather than business value.
Optimizing for Cost Per Qualified Outcome
A true reference architecture for production-ready AI agent infrastructure must optimize for 'Cost Per Qualified Outcome'. By utilizing advanced context engineering, the agent accurately resolves the intent in a fraction of the time. The infrastructure minimizes token usage through deduplication and semantic caching, drastically lowering LLM API costs. Furthermore, by seamlessly integrating with internal APIs, the agent completes the task (the outcome) autonomously, providing a concrete, measurable ROI that generic cost-savings models fail to capture.
Implementation Blueprint: A Step-by-Step Guide
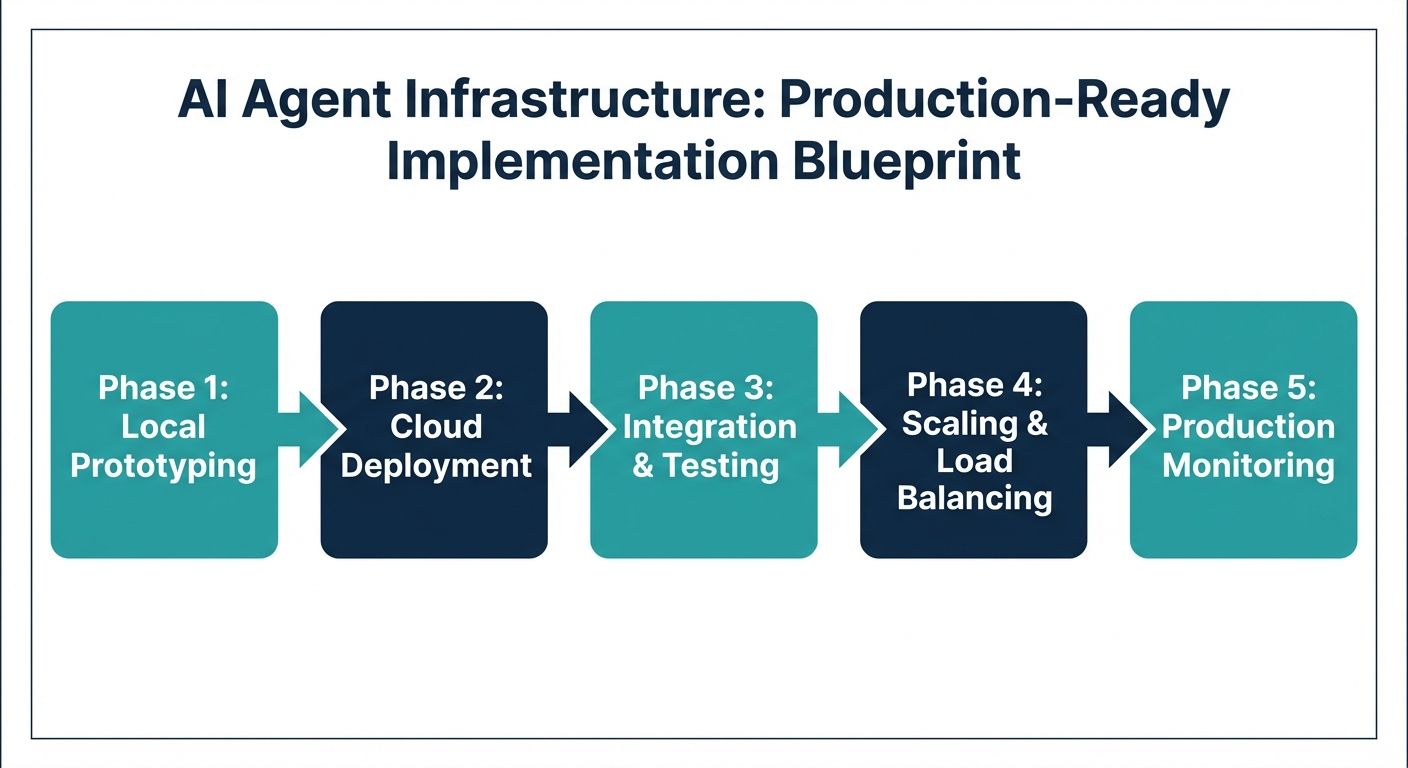
Building this robust infrastructure requires a structured, phased approach. Here is the definitive migration blueprint for technical integration, data migration, and deployment.
Step 1: Foundational Infrastructure Setup
Begin by establishing the networking and compute baseline. Deploy a scalable container orchestration platform (like Kubernetes) across multiple availability zones. Set up your streaming telephony gateways using WebSockets to ensure persistent, bi-directional audio streaming. Provision your specialized datastores: a relational database for user metadata, an in-memory store for real-time conversational state, and a highly available vector database for semantic search.
Step 2: Context Pipeline Integration
Implement the Alchemyst Kathan engine or a comparable context arithmetic pipeline. Ingest your enterprise data (PDFs, knowledge bases, historical tickets) through a data pipeline that chunks, embeds, and indexes the documents. Configure the metadata schemas to ensure secure, tenant-isolated data retrieval. Establish the necessary API endpoints that the agent will use as 'tools' to interact with your CRM, ERP, or billing systems.
Step 3: Orchestration and Agent Logic
Develop the core agentic loop. Rather than hardcoding conversational flows, define the system prompts, tool schemas, and guardrails. Implement the asynchronous streaming logic that ties the STT, LLM, and TTS together. Ensure that the orchestration layer includes dynamic interrupt handling, allowing the system to instantly halt TTS playback and clear the LLM generation buffer if the human user interrupts the agent.
Step 4: MLOps, Versioning, and Deployment
Integrate your agent lifecycle management tools. Implement a shadow testing environment where historical call transcripts are re-run against new agent versions to verify that the 'Cost Per Qualified Outcome' remains optimal. Configure the CI/CD pipeline to deploy changes securely, with automated rollbacks if latency metrics exceed predefined thresholds. Finally, establish the Human-in-the-Loop escalation routing, ensuring agents seamlessly transfer context to human operators when confidence scores drop.
Real-World Industry Use Cases and ROI
Implementing a production-ready AI agent infrastructure fundamentally transforms customer lifecycle management. In the financial services sector, context-aware voice agents handle complex debt collection and payment restructuring negotiations. Instead of following a rigid script, the agent dynamically retrieves the user's payment history, runs mathematical set-operations to determine eligible payment plans via the context pipeline, and negotiates securely in real-time. In healthcare, patient triage agents utilize strict RBAC and HIPAA-compliant infrastructure to schedule appointments, leveraging semantic similarity to match reported symptoms with appropriate specialist routing. By migrating from generic per-minute vendor solutions to a highly optimized, context-driven architecture, enterprises consistently report a reduction in average handle time and a massive leap in successful first-call resolutions.
Conclusion
Designing a reference architecture for production-ready AI agent infrastructure is a complex engineering challenge that extends far beyond the capabilities of basic API wrappers. It requires a deep commitment to advanced MLOps, rigorous security governance, low-latency streaming architectures, and most importantly, sophisticated context engineering. By moving away from brittle prompt engineering and adopting computational context arithmetic pipelines like Alchemyst's Kathan engine, enterprises can finally bridge the demo-to-deployment gap. By focusing on the 'Cost Per Qualified Outcome' and building resilient, context-aware infrastructure, businesses can unlock the true operational ROI of autonomous AI voice OS adoption.




